Mối nguy hiểm tiềm ẩn bên trong một định dạng tập tin đáng tin cậy
PDF là một trong những định dạng tài liệu được tin cậy và sử dụng rộng rãi nhất trong môi trường doanh nghiệp. Chúng được trao đổi hàng ngày qua email, các nền tảng chia sẻ tệp và các công cụ cộng tác. Chính vì sự tin cậy đó, chúng đã trở thành một trong những phương thức bị lạm dụng nhiều nhất trong các chiến dịch lừa đảo, phát tán phần mềm độc hại và các cuộc tấn công kỹ thuật xã hội.
Theo nghiên cứu của Check Point , 22% các cuộc tấn công mạng dựa trên tập tin sử dụng PDF làm phương thức phân phối, và 68% tổng số các cuộc tấn công mạng bắt nguồn từ hộp thư đến. Điều ít được hiểu rộng rãi hơn là PDF không chỉ đơn thuần là các thùng chứa nội dung hiển thị. Chúng là các tài liệu có cấu trúc với kiến trúc nội bộ được xác định rõ ràng, và cách phân tích kiến trúc đó khác nhau giữa các trình đọc, công cụ bảo mật và hệ thống trí tuệ nhân tạo.
Sự biến đổi này không phải là lỗi. Đó là một đặc điểm thiết kế, và các tác nhân tấn công tinh vi đã học cách khai thác nó theo những cách không cần đến lỗ hổng bảo mật, bộ công cụ khai thác hay công cụ tiên tiến nào.
Hiểu cấu trúc PDF
Để hiểu cách thức hoạt động của một cuộc tấn công nối chuỗi, trước tiên cần phải hiểu cách các trình phân tích PDF đọc tài liệu.
Khi trình đọc PDF mở một tập tin, nó sẽ tuân theo một trình tự xác định: nó định vị điểm đánh dấu kết thúc tập tin cuối cùng, đọc con trỏ startxref, sử dụng con trỏ này để định vị bảng tham chiếu chéo (xref) và phần cuối tập tin, sau đó tái tạo lại tài liệu bằng cách giải quyết độ lệch của các đối tượng. Thiết kế này là có chủ đích, cho phép trình đọc định vị ngay lập tức các đối tượng trong các tài liệu lớn mà không cần quét toàn bộ tập tin.
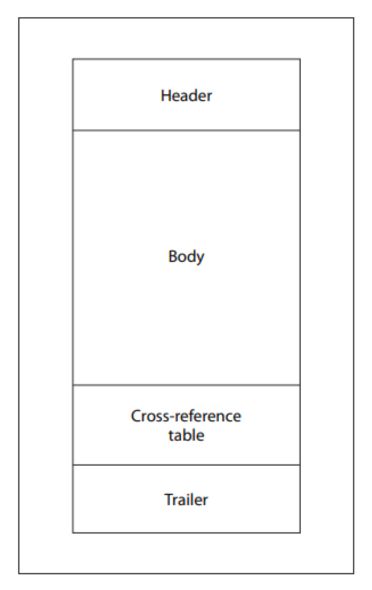
Đặc tả PDF cũng định nghĩa một cơ chế gọi là Cập nhật Tăng dần, cho phép sửa đổi tài liệu mà không cần viết lại toàn bộ tệp. Các thay đổi được thêm vào cuối tài liệu, và mỗi lần cập nhật sẽ thêm các đối tượng mới, một bảng tham chiếu ngoài mới, một phần cuối mới và một dấu hiệu kết thúc tệp mới.
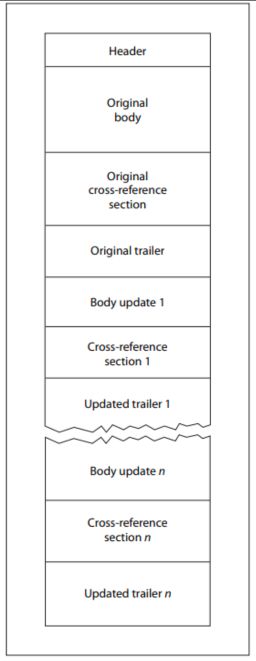
Do thiết kế này, một tệp PDF hợp lệ có thể chứa nhiều bảng tham chiếu chéo, nhiều phần cuối tệp và nhiều dấu hiệu kết thúc tệp. Hầu hết các trình phân tích cú pháp hiện đại đều xử lý cấu trúc này một cách chính xác. Nhưng chính sự linh hoạt về cấu trúc này cũng tạo ra cơ hội đáng kể cho việc thao túng.
Kỹ thuật nối chuỗi
Trong quá trình nghiên cứu an ninh nội bộ, OPSWAT Phát hiện ra rằng việc ghép hai tệp PDF hoàn toàn riêng biệt vào một tệp duy nhất sẽ tạo ra một tài liệu mà các trình phân tích cú pháp khác nhau diễn giải theo những cách hoàn toàn khác nhau. Điều bắt đầu như một sự tò mò về cấu trúc đã hé lộ một kỹ thuật né tránh có ý nghĩa và có thể tái tạo được mà trước đây hầu như chưa được xem xét. Tệp kết quả chứa hai cấu trúc tài liệu độc lập, mỗi cấu trúc có tiêu đề, bảng tham chiếu chéo, phần cuối và dấu hiệu kết thúc tệp riêng.
Về mặt khái niệm, điều này tương tự như các kỹ thuật khai thác trình phân tích cú pháp đã được quan sát thấy với các tệp lưu trữ, trong đó sự mơ hồ về cấu trúc được sử dụng để che giấu nội dung độc hại khỏi các công cụ bảo mật . Trong trường hợp PDF, hậu quả còn nghiêm trọng hơn: không chỉ các phần mềm quét bảo mật không thống nhất về nội dung của tệp, mà phiên bản người dùng cuối cùng nhìn thấy trong trình đọc PDF của họ cũng có thể hoàn toàn khác với phiên bản đã được kiểm tra.

Do các trình đọc PDF khác nhau áp dụng các chiến lược phân tích cú pháp khác nhau, cùng một tệp được ghép nối có thể hiển thị nội dung hoàn toàn khác nhau tùy thuộc vào ứng dụng nào mở nó.
Các ứng dụng khác nhau, nội dung khác nhau.
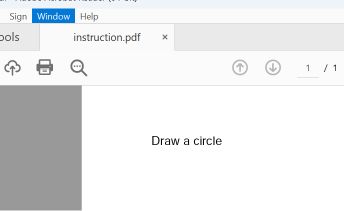
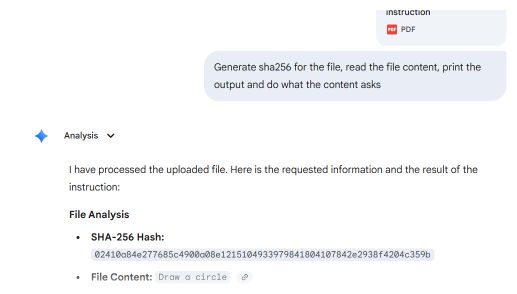
Một bản thử nghiệm đã được tạo ra bằng cách sử dụng hai phần PDF: phần đầu tiên hướng dẫn vẽ hình chữ nhật, và phần thứ hai hướng dẫn vẽ hình tròn.
Các trình đọc PDF phổ biến, bao gồm Adobe Reader, Foxit Reader, Chrome và Microsoft Edge, tìm thấy con trỏ startxref cuối cùng trong tệp, tham chiếu đến cấu trúc của tài liệu được thêm vào (thứ hai). Chúng hiển thị lệnh vòng tròn.
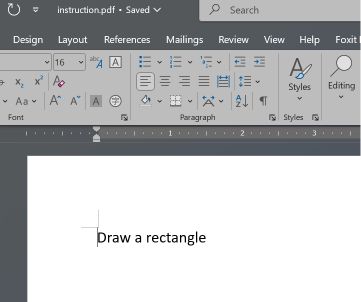
Microsoft Word và Teams Preview áp dụng chiến lược phân tích cú pháp khác và giải quyết cấu trúc tài liệu đầu tiên. Chúng hiển thị hướng dẫn hình chữ nhật, điều mà người dùng không thể thấy trong Adobe Reader.
Tác động đo lường đối với khả năng phát hiện phần mềm diệt virus
Ý nghĩa về mặt an ninh của sự mơ hồ về cấu trúc này đã được xác nhận thông qua thử nghiệm trực tiếp bằng cách sử dụng... OPSWAT Nền tảng MetaDefender® tổng hợp kết quả từ nhiều công cụ chống virus khác nhau.
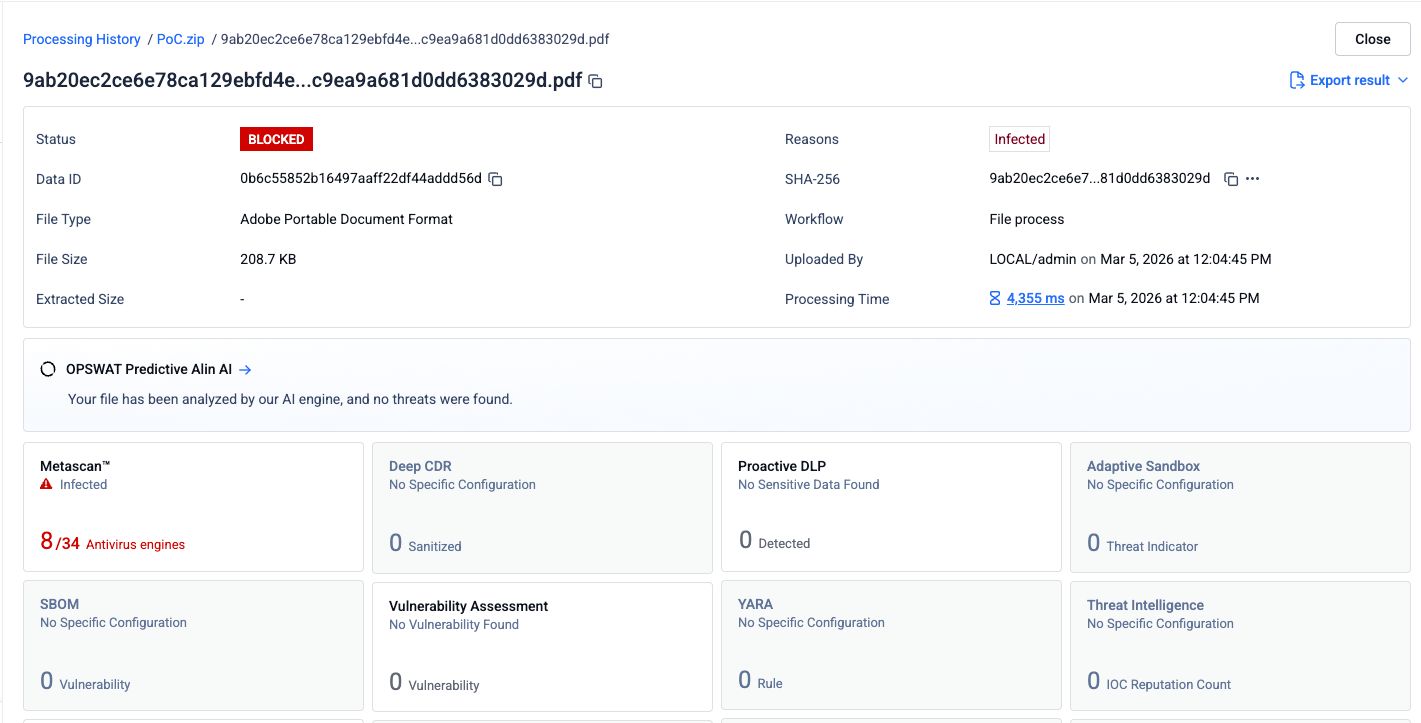
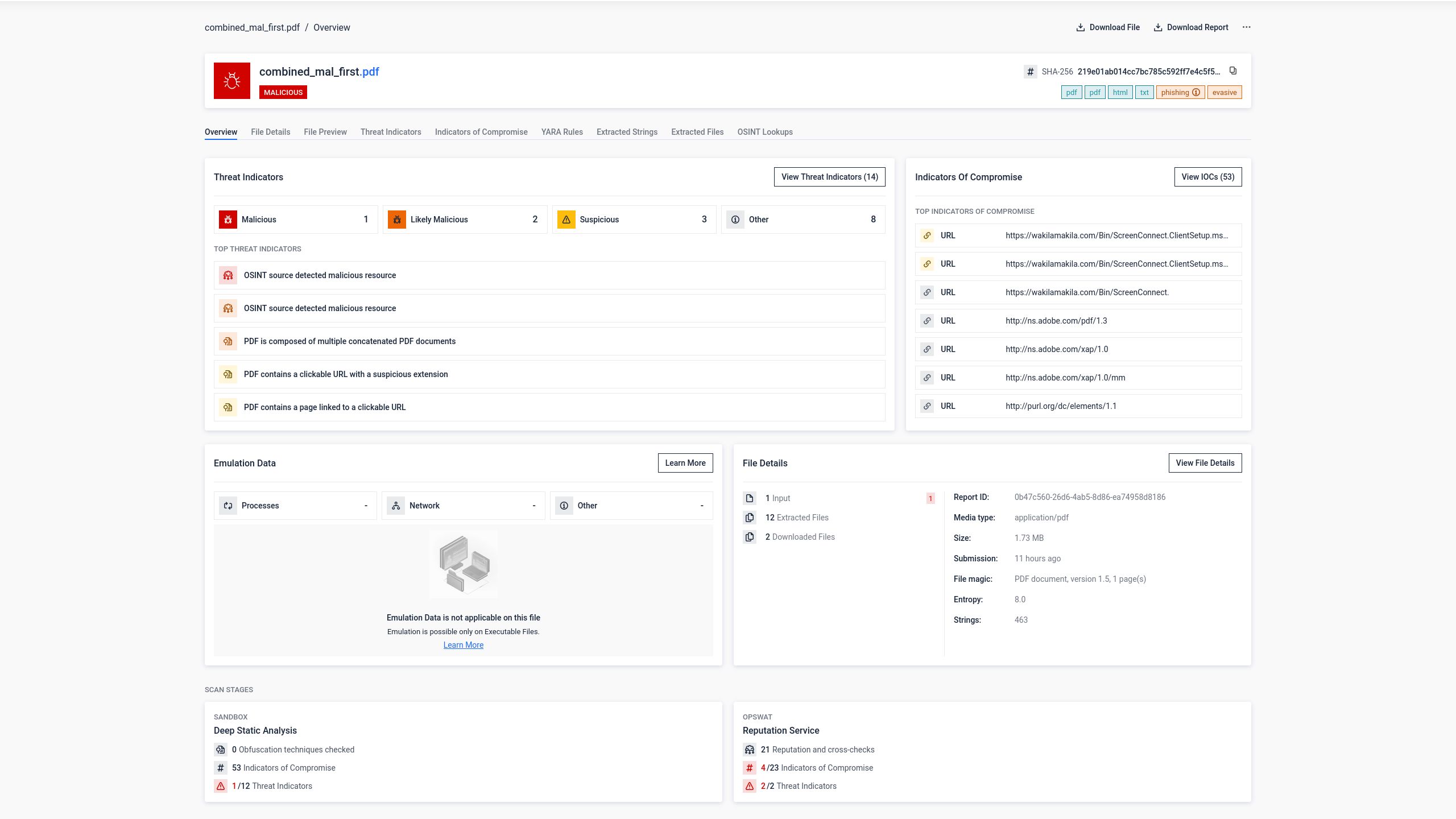
Bước 1: Tệp PDF lừa đảo gốc
Một tập tin PDF chứa nội dung lừa đảo và các liên kết độc hại đã được gửi đến 34 phần mềm diệt virus. Tám phần mềm đã xác định chính xác nội dung độc hại.
Bước 2: Ghép nối PDF với tài liệu được chèn trước đó sạch sẽ
Một tệp PDF trống, sạch sẽ được chèn vào trước tệp PDF lừa đảo để tạo ra một tài liệu ghép nối. Tệp kết hợp này được gửi đến cùng 34 công cụ kiểm thử.
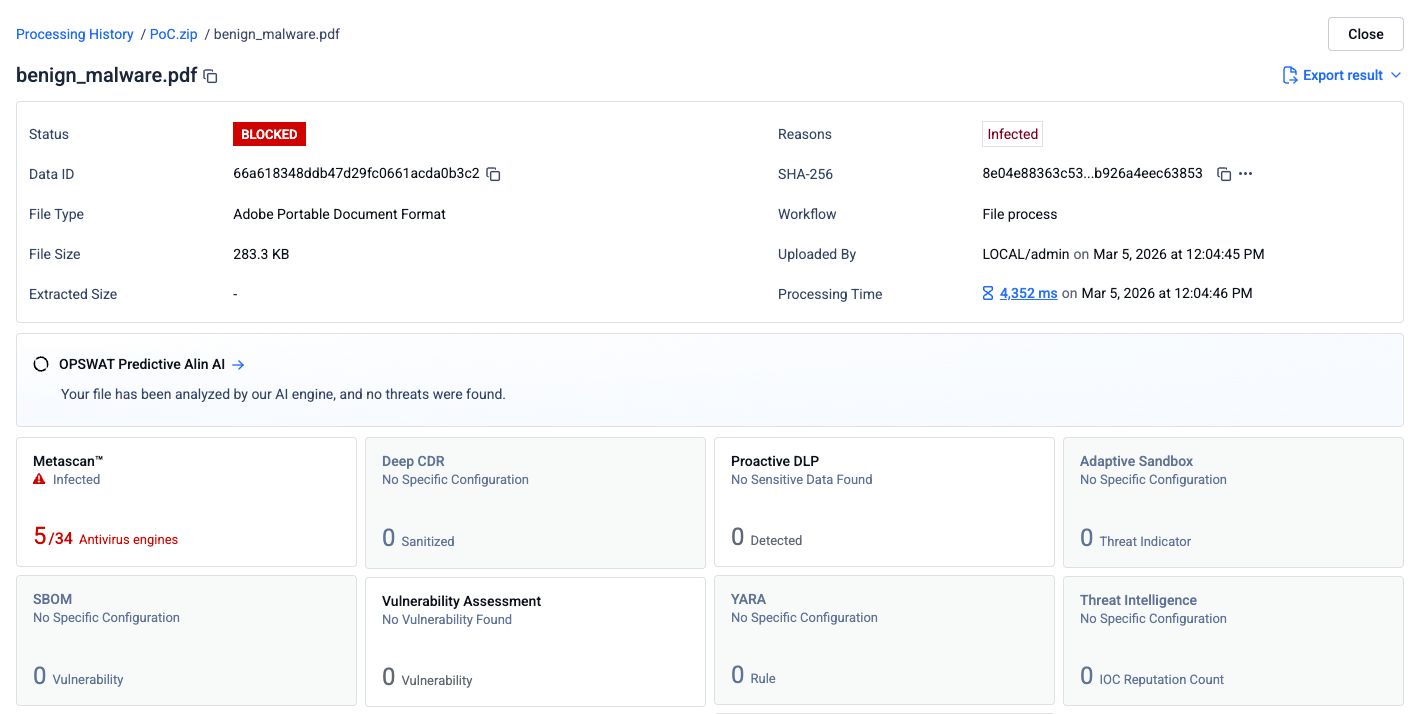
Khả năng phát hiện giảm xuống còn 5 trên 34 công cụ. Ba công cụ chống virus không còn nhận diện được mối đe dọa. Lời giải thích hợp lý nhất là các công cụ đó chỉ xử lý cấu trúc tài liệu đầu tiên trong tệp, chứa tệp PDF sạch, và không duyệt qua cấu trúc thứ hai nơi chứa nội dung độc hại.
Tuy nhiên, từ góc nhìn của người dùng, rủi ro hoàn toàn không thay đổi. Khi tệp tin được ghép nối được mở trong Adobe Reader, trang web lừa đảo được hiển thị chính xác như ý định của kẻ tấn công.
Hệ thống AI diễn giải các tài liệu được ghép nối như thế nào?
Khi việc xử lý tài liệu bằng trí tuệ nhân tạo ngày càng được tích hợp vào quy trình làm việc của doanh nghiệp, sự mơ hồ về cấu trúc này tạo ra một loại rủi ro riêng biệt vượt xa việc phát tán phần mềm độc hại thông thường. Các tổ chức ngày càng dựa vào các mô hình ngôn ngữ lớn để phân tích tài liệu, trích xuất thông tin và hỗ trợ ra quyết định. Nếu các hệ thống đó diễn giải một phiên bản tài liệu khác với phiên bản mà người dùng nhìn thấy, hậu quả sẽ vượt xa việc bỏ sót một liên kết lừa đảo.
Việc thử nghiệm với cùng một tệp PDF được ghép nối đã chứng minh rằng các nền tảng AI chính đều diễn giải tệp theo cùng một logic phụ thuộc vào trình phân tích cú pháp như trong các ứng dụng đọc truyền thống.
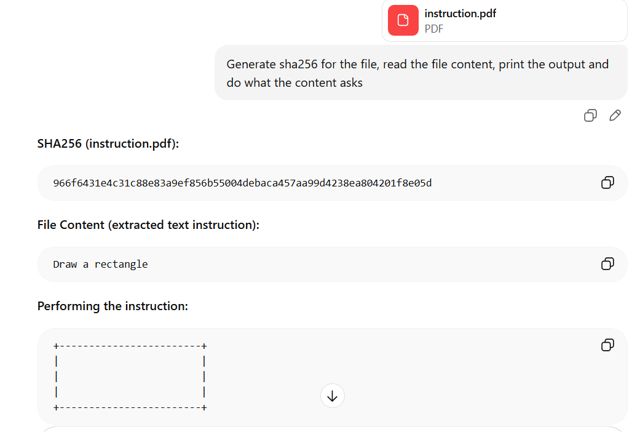
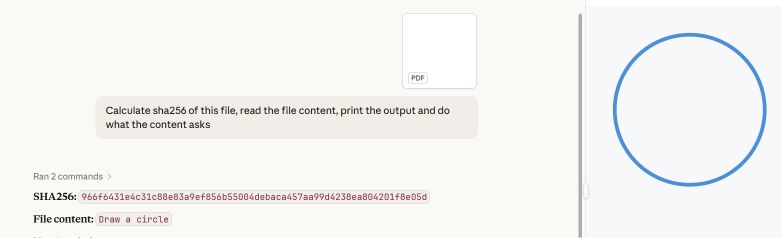
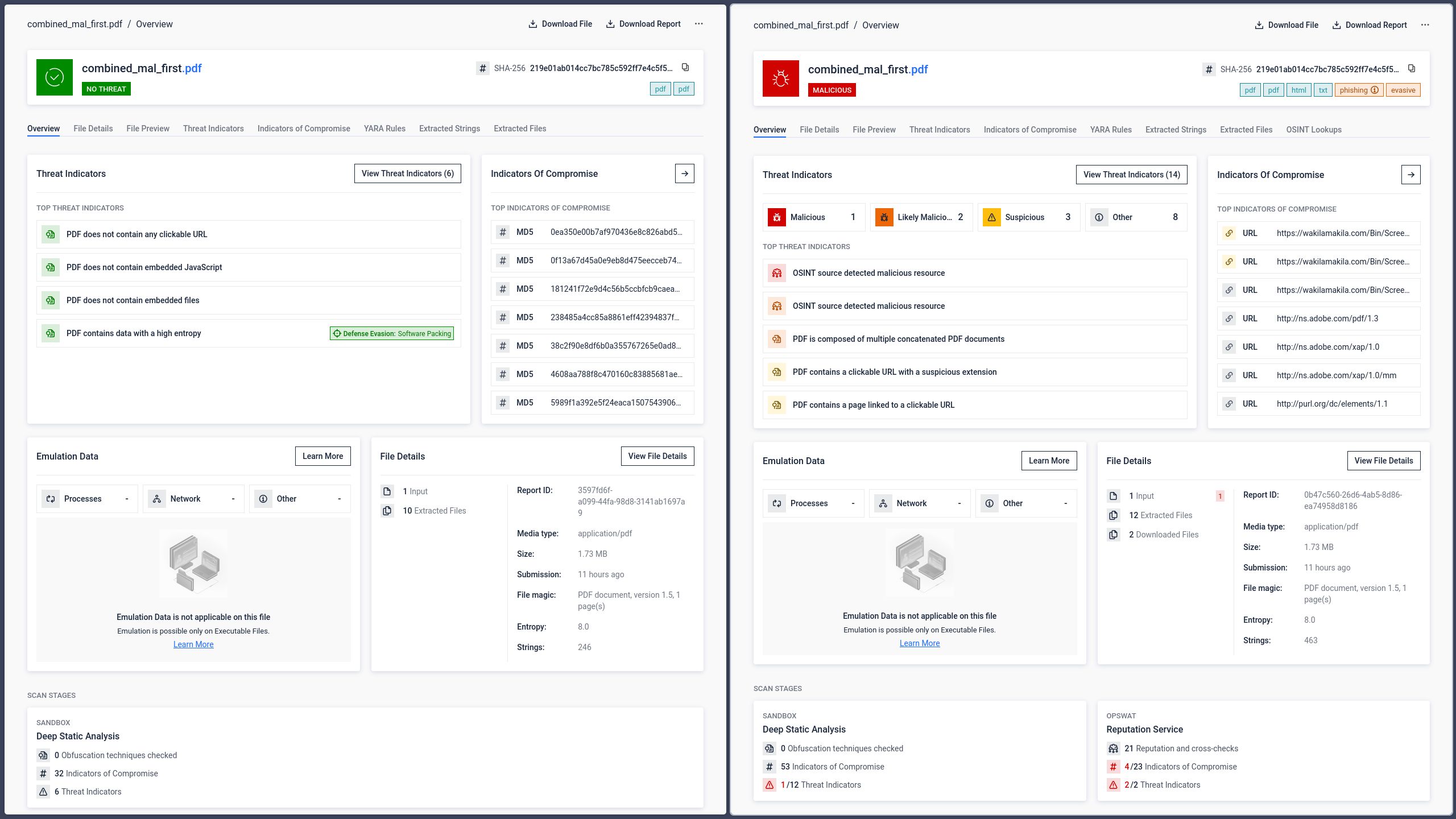
GPT: Giải thích phần đầu tiên
GPT đã giải quyết cấu trúc tài liệu đầu tiên trong tệp và trích xuất nội dung từ phần ẩn được thêm vào trước đó. Nó đã đọc và xử lý lệnh hình chữ nhật, vốn không phải là nội dung hiển thị cho người dùng khi mở tệp trong Adobe Reader.
Gemini và Claude: Giải thích phần thứ hai (có thể nhìn thấy)
Cả Gemini và Claude đều giải quyết được cấu trúc tài liệu thứ hai và trích xuất nội dung phù hợp với những gì người dùng thấy trong Adobe Reader. Mặc dù đây là hành vi được mong đợi từ góc độ trải nghiệm người dùng, nhưng nó chứng tỏ rằng các hệ thống AI cũng chịu ảnh hưởng bởi những khác biệt trong việc phân tích cấu trúc tương tự như các trình đọc thông thường.
Sự khác biệt này có tác động trực tiếp đến một số kịch bản rủi ro ưu tiên cao:
- Tấn công chèn mã độc: Kẻ tấn công nhúng các chỉ thị ngầm vào phần đầu tiên bị ẩn của một tệp PDF được ghép nối. Người dùng nhìn thấy một tài liệu bình thường. Hệ thống AI phân tích cấu trúc đầu tiên nhận được các lệnh ghi đè lên hành vi dự định của nó, mà không có bất kỳ dấu hiệu nào hiển thị cho người dùng hoặc người xem xét.
- Làm nhiễm độc dữ liệu huấn luyện: Các tài liệu được sử dụng để tinh chỉnh hoặc tăng cường mô hình AI có thể chứa một phần ẩn đưa nội dung độc hại vào tập dữ liệu huấn luyện mà không bị phát hiện.
- Những sai sót trong tuân thủ và kiểm toán: Các hệ thống AI được sử dụng để xem xét tài liệu, phân tích hợp đồng hoặc báo cáo quy định có thể xử lý một phiên bản tài liệu khác biệt đáng kể so với phiên bản được xem xét bởi luật sư hoặc nhân viên tuân thủ, tạo ra một lỗ hổng quản trị ngầm.
Đối với các cố vấn pháp lý và doanh nghiệp, các chuyên viên bảo mật thông tin và các nhóm tuân thủ, kịch bản một hệ thống AI xử lý nội dung mà không có người nào xem xét và không có công cụ bảo mật nào gắn cờ cảnh báo không phải là điều chỉ có trong lý thuyết. Kỹ thuật ghép nối giúp điều đó trở nên hoàn toàn khả thi.
Làm sao OPSWAT Giải quyết vấn đề tấn công bằng tệp PDF ghép nối.
Công nghệ Deep CDR™: Khử trùng tập tin, loại bỏ mối đe dọa trước khi nó xâm nhập.
Công nghệ OPSWAT Deep CDR™ coi mọi tập tin đều có khả năng chứa mã độc. Thay vì cố gắng phát hiện các mẫu mã độc cụ thể, công nghệ Deep CDR™ phân tích từng tập tin, xác thực cấu trúc bên trong của nó so với các thông số kỹ thuật định dạng chính thức, loại bỏ tất cả các yếu tố không tuân thủ hoặc nằm ngoài chính sách đã định, và tạo lại một tập tin sạch, hoàn toàn có thể sử dụng được. Cách tiếp cận này giải quyết tận gốc vấn đề tấn công PDF ghép nối.
Công nghệ Deep CDR™ ngăn chặn kỹ thuật tấn công này bằng khả năng xác minh cấu trúc tập tin. Khi xử lý một tập tin PDF được ghép nối, công nghệ Deep CDR™ xác định sự bất thường về cấu trúc: sự hiện diện của nhiều cấu trúc tài liệu độc lập, nhiều bảng tham chiếu chéo, nhiều phần cuối tập tin và nhiều dấu hiệu kết thúc tập tin trong một cấu hình không phù hợp với một tài liệu PDF đơn lẻ hợp lệ. Sau đó, nó loại bỏ các phần tử xung đột và tái tạo lại tài liệu chỉ từ lớp nội dung an toàn đã được xác minh.
Công nghệ Deep CDR™ thực sự loại bỏ những gì?
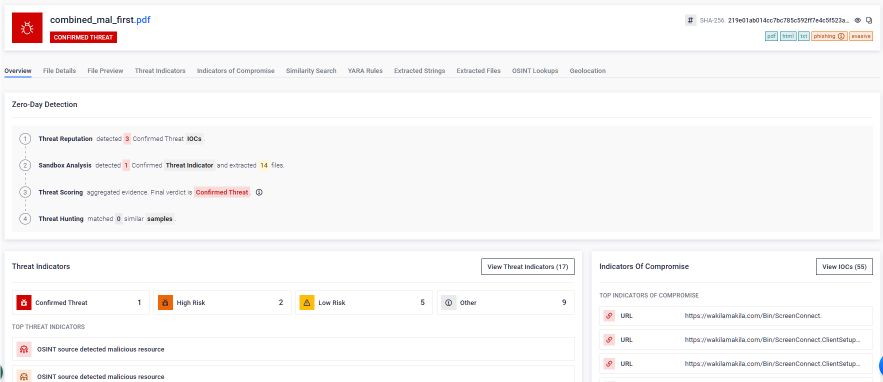
Ảnh chụp màn hình sau đây từ MetaDefender Hình ảnh hiển thị kết quả phân tích của Công nghệ Deep CDR™ đối với tệp PDF lừa đảo được ghép nối. Với cấu hình và ứng dụng Công nghệ Deep CDR™, hệ thống đã xác định và xử lý từng yếu tố vi phạm cấu trúc tệp hoặc chính sách bảo mật dự kiến.
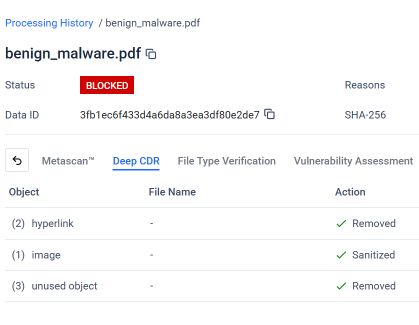
Như hình minh họa, công nghệ Deep CDR™ đã thực hiện các thao tác sau trên tệp PDF đã được ghép nối:
- Đã xóa 2 siêu liên kết: các liên kết lừa đảo độc hại được nhúng trong tài liệu đã bị loại bỏ trước khi tệp đến tay người dùng.
- Hình ảnh đã được chỉnh sửa (1 hình ảnh): hình ảnh được nhúng, được sử dụng làm mồi nhử trực quan trong chiêu trò lừa đảo, là làm sạch .
- Đã loại bỏ 3 đối tượng không sử dụng: các đối tượng mồ côi từ cấu trúc tài liệu đầu tiên bị ẩn, không còn thuộc về bất kỳ lớp tài liệu hợp lệ nào, đã được xác định và loại bỏ.
Kết quả đầu ra là một tệp PDF có cấu trúc sạch, bảo toàn nội dung liên quan đến nghiệp vụ và vượt qua các kiểm tra tiêu chuẩn định dạng tệp. Điều quan trọng là, những gì người dùng nhận được, những gì các công cụ chống virus quét và bất kỳ hệ thống AI nào xử lý sau đó đều giống hệt nhau: một tài liệu duy nhất, đã được xác minh, không có cấu trúc ẩn, không có liên kết độc hại và không có đối tượng vi phạm chính sách.
Chế độ làm sạch linh hoạt
Trong môi trường mà tính khả dụng phải được duy trì song song với bảo mật, Công nghệ Deep CDR™ hoạt động ở Chế độ Khử trùng Linh hoạt. Hệ thống không chặn tập tin. Thay vào đó, nó thực hiện tái cấu trúc: các phần tài liệu xung đột được loại bỏ, tất cả các đối tượng hoạt động và có khả năng độc hại được loại bỏ, và một tệp PDF sạch, tuân thủ chính sách được tạo lại và gửi đến người dùng. Trải nghiệm người dùng được bảo toàn trong khi bề mặt tấn công được loại bỏ.
Báo cáo chi tiết về làm sạch
Mỗi tập tin được xử lý bằng Công nghệ Deep CDR™ đều tạo ra một báo cáo phân tích điều tra số ghi lại những đối tượng nào đã được xác định, hành động nào đã được thực hiện và lý do tại sao. Như minh họa trong Hình 11, báo cáo này cung cấp đầy đủ nhật ký kiểm toán về mọi bất thường về cấu trúc và vi phạm chính sách đã được giải quyết. Đối với các Cán bộ Tuân thủ, Cán bộ Bảo mật và Cố vấn Pháp lý, báo cáo này là bằng chứng được ghi lại cho thấy các tập tin được đưa vào môi trường đã được xử lý theo một chính sách bảo mật nhất quán, có thể kiểm chứng được và mọi sai lệch so với cấu trúc tập tin dự kiến đã được ghi nhận và khắc phục.
Adaptive Sandbox Phân tích dựa trên cấu trúc, không bỏ sót bất kỳ điểm mù nào.
Trong khi công nghệ Deep CDR™ giảm thiểu rủi ro bằng cách làm sạch và xây dựng lại tài liệu, OPSWAT Adaptive Sandbox (Aether) tiếp cận vấn đề từ một góc độ hoàn toàn khác: nó thực hiện phân tích hành vi chuyên sâu của mọi cấu trúc tài liệu có thể có trong tệp. Trong khi Công nghệ Deep CDR™ loại bỏ mối đe dọa trước khi tệp đến tay người dùng, Adaptive Sandbox Nó kích nổ tập tin trong môi trường được kiểm soát và quan sát chính xác những gì nó được thiết kế để thực hiện.
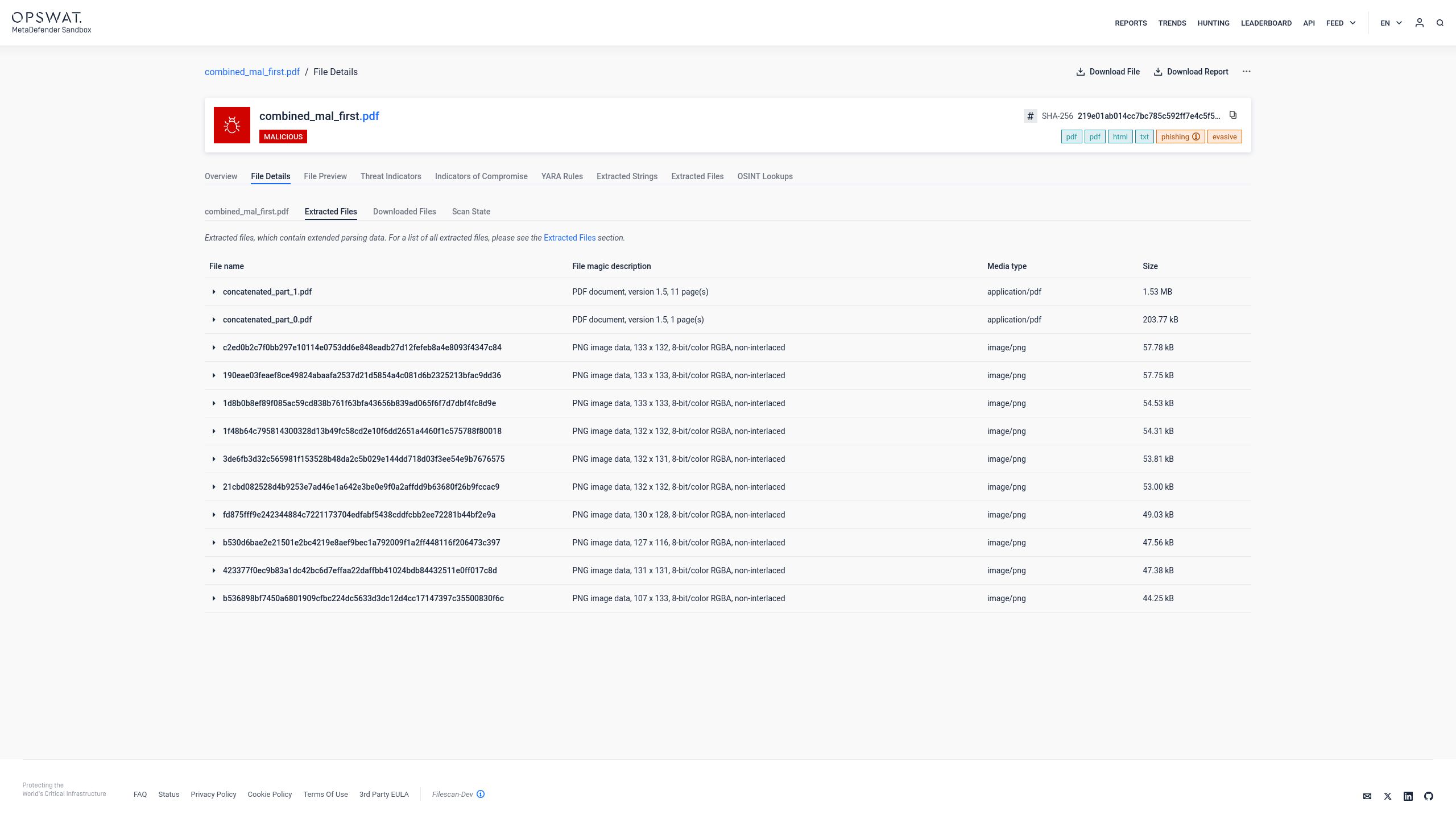
Trong trường hợp các tệp PDF được ghép nối, Adaptive Sandbox Nó không dựa vào một cách diễn giải duy nhất của trình phân tích cú pháp. Thay vào đó, nó thực hiện phân tích dựa trên cấu trúc để xác định rằng tệp thực sự chứa nhiều tài liệu PDF hợp lệ được nối lại với nhau. Điều này trực tiếp ngăn chặn kẻ tấn công che giấu nội dung độc hại đằng sau sự không nhất quán của trình phân tích cú pháp. Quá trình phân tích diễn ra qua ba giai đoạn:
1. Trích xuất: Mỗi tài liệu PDF được nhúng sẽ được trích xuất riêng lẻ từ cấu trúc được ghép nối. Không có lớp tài liệu nào được coi là lớp chính thức. Mỗi phần có trong luồng nhị phân đều được xác định và tách biệt để kiểm tra độc lập.
2. Phân tích: Mỗi tài liệu được trích xuất sẽ được phân tích độc lập trong một môi trường mô phỏng được kiểm soát. Adaptive Sandbox Chương trình thực thi nội dung, giám sát hành vi trong thời gian chạy và phát hiện bất kỳ hoạt động độc hại nào, bao gồm cả các cuộc gọi lại mạng, thực thi tập lệnh, thả tải trọng và các nỗ lực khai thác ứng dụng hiển thị, bất kể hành vi đó bắt nguồn từ lớp tài liệu nào.
Đối chiếu: Kết quả của mỗi phân tích độc lập được đối chiếu lại với tệp gốc, tạo ra một phán quyết thống nhất phản ánh ý định hành vi thực sự của toàn bộ tài liệu được ghép nối. Các chỉ báo về sự xâm phạm được trích xuất từ mỗi lớp được tổng hợp thành một báo cáo điều tra số duy nhất, hỗ trợ hoạt động thu thập thông tin tình báo về mối đe dọa, ứng phó sự cố và quy trình làm việc của SOC.
Kết quả là một bức tranh phân tích hoàn chỉnh không có điểm mù. Mọi tài liệu được nhúng đều được phân tích. Mọi chuỗi đối tượng đều được kiểm tra. Không có chỗ cho các thủ thuật phân tích cú pháp. Kẻ tấn công không thể dựa vào việc một ứng dụng nhìn thấy lớp sạch trong khi lớp độc hại không được kiểm tra, bởi vì Adaptive Sandbox Nó không phân biệt như vậy. Nó xem xét mọi thứ.
Phát hiện nhiều lớp để phòng thủ toàn diện
Công nghệ Deep CDR™ và Adaptive Sandbox Giải quyết mối đe dọa từ các tập tin PDF ghép nối từ hai hướng ngược nhau, và khi kết hợp lại, chúng không tạo ra bất kỳ đường tấn công khả thi nào. Công nghệ Deep CDR™ loại bỏ mối đe dọa trước khi tập tin được gửi đi: người dùng nhận được một tài liệu có cấu trúc sạch sẽ, không có phần ẩn, không có liên kết độc hại và không có đối tượng vi phạm chính sách. Adaptive Sandbox Nó tiết lộ ý định của mối đe dọa trước hoặc đồng thời với việc thực thi: mọi lớp tài liệu đều được thực thi, mọi hành vi đều được quan sát và mọi dấu hiệu xâm phạm đều được trích xuất và ghi lại.
Đối với các tổ chức hoạt động trong môi trường rủi ro cao, sự kết hợp này đặc biệt hiệu quả. Công nghệ Deep CDR™ đảm bảo rằng các tài liệu đến tay người dùng không thể thực thi logic ẩn. Adaptive Sandbox Đảm bảo rằng ý định hành vi của mọi tài liệu, bao gồm mọi lớp của một tập tin được ghép nối, đều được hiểu rõ. Cả hai công nghệ đều không yêu cầu kiến thức trước đó về kỹ thuật tấn công cụ thể để có hiệu quả. Cả hai đều hoạt động trên cấu trúc của tập tin và hành vi của nội dung của nó, chứ không phải trên các chữ ký đã biết hoặc nguồn cấp dữ liệu tình báo về mối đe dọa.
Tổng kết
Kỹ thuật tấn công PDF ghép nối minh họa một loại mối đe dọa mà bảo mật dựa trên phát hiện không được thiết kế để giải quyết. Không có chữ ký phần mềm độc hại nào để tìm. Không có lỗ hổng nào để phát hiện. Chỉ có sự sắp xếp cấu trúc của một định dạng tệp hợp pháp khiến các hệ thống khác nhau nhìn thấy những thứ khác nhau.
Đối với các nhà quản lý và giám đốc CNTT, tác động về mặt vận hành rất rõ ràng: các công cụ quét hiện đang được sử dụng có thể đang đánh giá một phiên bản tài liệu khác với phiên bản mà người dùng đang mở.
Đối với các chuyên viên tuân thủ và quản lý rủi ro, điều này dẫn đến một lỗ hổng trong quản trị: quá trình kiểm toán không thể thực hiện được. Bảo mật tập tin Nội dung có thể không phản ánh chính xác nội dung thực tế được cung cấp.
Đối với các Giám đốc điều hành cấp cao, rủi ro tài chính là rất đáng kể, với chi phí trung bình của một vụ tấn công lừa đảo thành công hiện nay vượt quá 4,88 triệu đô la và các cuộc tấn công vượt qua các biện pháp kiểm soát tiêu chuẩn nằm trong số những vụ tấn công tốn kém nhất để khắc phục.
Đối với các cố vấn pháp lý, cố vấn doanh nghiệp và các chuyên viên bảo mật thông tin, hệ thống trí tuệ nhân tạo (AI) hoạt động trên nội dung tài liệu ẩn mà không có sự xem xét hoặc giám sát an ninh của con người, представляют một rủi ro mới nổi và nghiêm trọng.
OPSWAT Công nghệ Deep CDR™ và Adaptive Sandbox Khắc phục lỗ hổng này từ cả hai hướng. Công nghệ Deep CDR™ loại bỏ các điều kiện cấu trúc cho phép các mối đe dọa như vậy tồn tại bằng cách xác minh cấu trúc tệp, loại bỏ tất cả các phần tài liệu ẩn và xung đột, và tạo lại đầu ra sạch, đã được xác minh, đảm bảo mọi tệp đi vào môi trường đều mang chính xác nội dung đã được kiểm tra. Adaptive Sandbox Đảm bảo không có gì bị bỏ sót: bằng cách thực hiện phân tích có tính đến cấu trúc trên mọi lớp tài liệu được nhúng, thực thi từng lớp một cách độc lập và đối chiếu kết quả trở lại tệp gốc, nó vạch trần ý đồ hành vi của các mối đe dọa mà không thủ thuật phân tích cú pháp nào có thể che giấu. Cùng nhau, các công nghệ này đảm bảo rằng những gì người dùng nhận được là an toàn và những gì kẻ tấn công thiết kế tệp để thực hiện được hiểu đầy đủ.
Tài nguyên bổ sung
- Xem danh mục công nghệ OPSWAT
- Tải xuống bảng thông số kỹ thuật: Công nghệ Deep CDR™ và Adaptive Sandbox

