Giả mạo tệp tin vẫn là một trong những kỹ thuật hiệu quả nhất mà kẻ tấn công sử dụng để vượt qua các biện pháp kiểm soát bảo mật truyền thống. Năm ngoái, OPSWAT đã giới thiệu công cụ Phát hiện Loại Tệp được tăng cường AI để lấp đầy những thiếu sót mà các công cụ cũ để lại. Năm nay, với Mô hình Phát hiện Loại Tệp v3, chúng tôi đã nâng cao khả năng này bằng cách tập trung vào các loại tệp mà độ chính xác là yếu tố trọng yếu nhất, nơi các hệ thống dựa trên logic truyền thống thường xuyên gặp khó khăn.
OPSWAT Mô hình Phát hiện Loại Tệp v3 được thiết kế để giải quyết một thách thức cụ thể trong việc phân loại đáng tin cậy các tệp mơ hồ và phi cấu trúc, đặc biệt là các định dạng văn bản như tập lệnh, tệp cấu hình và mã nguồn. Không giống như các bộ phân loại tổng quát, mô hình này được xây dựng riêng cho các trường hợp sử dụng an ninh mạng, trong đó việc phân loại sai tập lệnh shell hoặc không phát hiện được tài liệu chứa macro nhúng, chẳng hạn như tệp Word có mã VBA, có thể gây ra rủi ro bảo mật đáng kể.
Tại sao việc phát hiện loại tệp thực sự trọng yếu
Hầu hết các hệ thống phát hiện đều dựa trên ba phương pháp phổ biến:
- Phần mở rộng tệp: Phương pháp này kiểm tra tên tệp để xác định loại tệp dựa trên phần mở rộng, chẳng hạn như .doc hoặc .exe. Phương pháp này nhanh chóng và tương thích rộng rãi trên nhiều nền tảng. Tuy nhiên, nó dễ bị thao túng. Một tệp độc hại có thể được đổi tên thành một phần mở rộng trông có vẻ an toàn, và một số hệ thống hoàn toàn bỏ qua phần mở rộng, khiến phương pháp này không đáng tin cậy.
- Byte ma thuật: Đây là các chuỗi cố định được tìm thấy ở đầu nhiều tệp có cấu trúc, chẳng hạn như PDF hoặc hình ảnh. Phương pháp này cải thiện độ chính xác so với phần mở rộng tệp bằng cách kiểm tra nội dung tệp thực tế. Nhược điểm là không phải tất cả các loại tệp đều có mẫu byte được xác định rõ ràng. Byte ma thuật cũng có thể bị giả mạo, và các tiêu chuẩn không nhất quán giữa các công cụ có thể dẫn đến nhầm lẫn.
- Phân tích Phân phối Ký tự: Phương pháp này phân tích nội dung thực tế của một tệp để suy ra loại tệp. Phương pháp này đặc biệt hữu ích để xác định các định dạng văn bản có cấu trúc lỏng lẻo, chẳng hạn như tập lệnh hoặc tệp cấu hình. Mặc dù cung cấp thông tin chi tiết sâu hơn, nhưng phương pháp này đi kèm với chi phí xử lý cao hơn và có thể tạo ra kết quả báo động giả với nội dung bất thường. Phương pháp này cũng kém hiệu quả hơn đối với các tệp nhị phân thiếu các mẫu ký tự dễ đọc.
Các phương pháp này hoạt động tốt với các định dạng có cấu trúc nhưng lại trở nên kém tin cậy khi áp dụng cho các tệp phi cấu trúc hoặc dạng văn bản. Ví dụ: một tập lệnh shell với số lượng lệnh tối thiểu có thể rất giống với một tệp văn bản thuần túy. Nhiều tệp trong số này thiếu tiêu đề mạnh hoặc các dấu hiệu nhất quán, khiến việc phân loại dựa trên mẫu byte hoặc phần mở rộng trở nên không đủ. Kẻ tấn công lợi dụng sự mơ hồ này để ngụy trang các tập lệnh độc hại thành các tài liệu hoặc nhật ký vô hại.
Các công cụ cũ như TrID và LibMagic không được thiết kế cho mức độ tinh tế này. Mặc dù hiệu quả trong việc phân loại tệp chung, chúng được tối ưu hóa về phạm vi và tốc độ, chứ không phải để phát hiện chuyên biệt trong điều kiện bảo mật hạn chế.
Mô hình phát hiện loại tệp v3 hoạt động như thế nào
Quy trình huấn luyện Mô hình Phát hiện Kiểu Tệp v3 bao gồm hai giai đoạn. Ở giai đoạn đầu, quá trình huấn luyện trước thích ứng với miền được thực hiện bằng Mô hình Ngôn ngữ Che giấu (MLM), cho phép mô hình học các mẫu cú pháp và cấu trúc cụ thể theo miền. Ở giai đoạn thứ hai, mô hình được tinh chỉnh trên một tập dữ liệu có giám sát, trong đó mỗi tệp được chú thích rõ ràng với kiểu tệp thực của nó.
Bộ dữ liệu là sự kết hợp có chọn lọc giữa các tệp thông thường và các mẫu mối đe dọa, đảm bảo sự cân bằng mạnh mẽ giữa độ chính xác trong thế giới thực và tính liên quan đến bảo mật. OPSWAT duy trì quyền kiểm soát dữ liệu đào tạo, cho phép tinh chỉnh liên tục các định dạng trọng yếu nhất đối với hoạt động bảo mật.
Thành phần AI được áp dụng một cách chính xác chứ không phải rộng rãi. Mô hình Phát hiện Loại Tệp v3 tập trung vào các loại tệp mơ hồ và phi cấu trúc mà các phương pháp phát hiện truyền thống không thể xử lý hiệu quả, chẳng hạn như tập lệnh, nhật ký và văn bản có định dạng lỏng lẻo, trong đó cấu trúc không nhất quán hoặc không có. Thời gian suy luận trung bình vẫn dưới 50 mili giây, giúp mô hình này hiệu quả cho các quy trình làm việc thời gian thực trên các tệp tải lên an toàn, thực thi thiết bị đầu cuối và quy trình tự động hóa.
Kết quả chuẩn
Chúng tôi đã đánh giá chuẩn OPSWAT Công cụ Phát hiện Loại Tệp so với các công cụ phát hiện loại tệp hàng đầu sử dụng một tập dữ liệu lớn và đa dạng. So sánh bao gồm điểm F1 trên 248.000 tệp và khoảng 100 loại tệp.
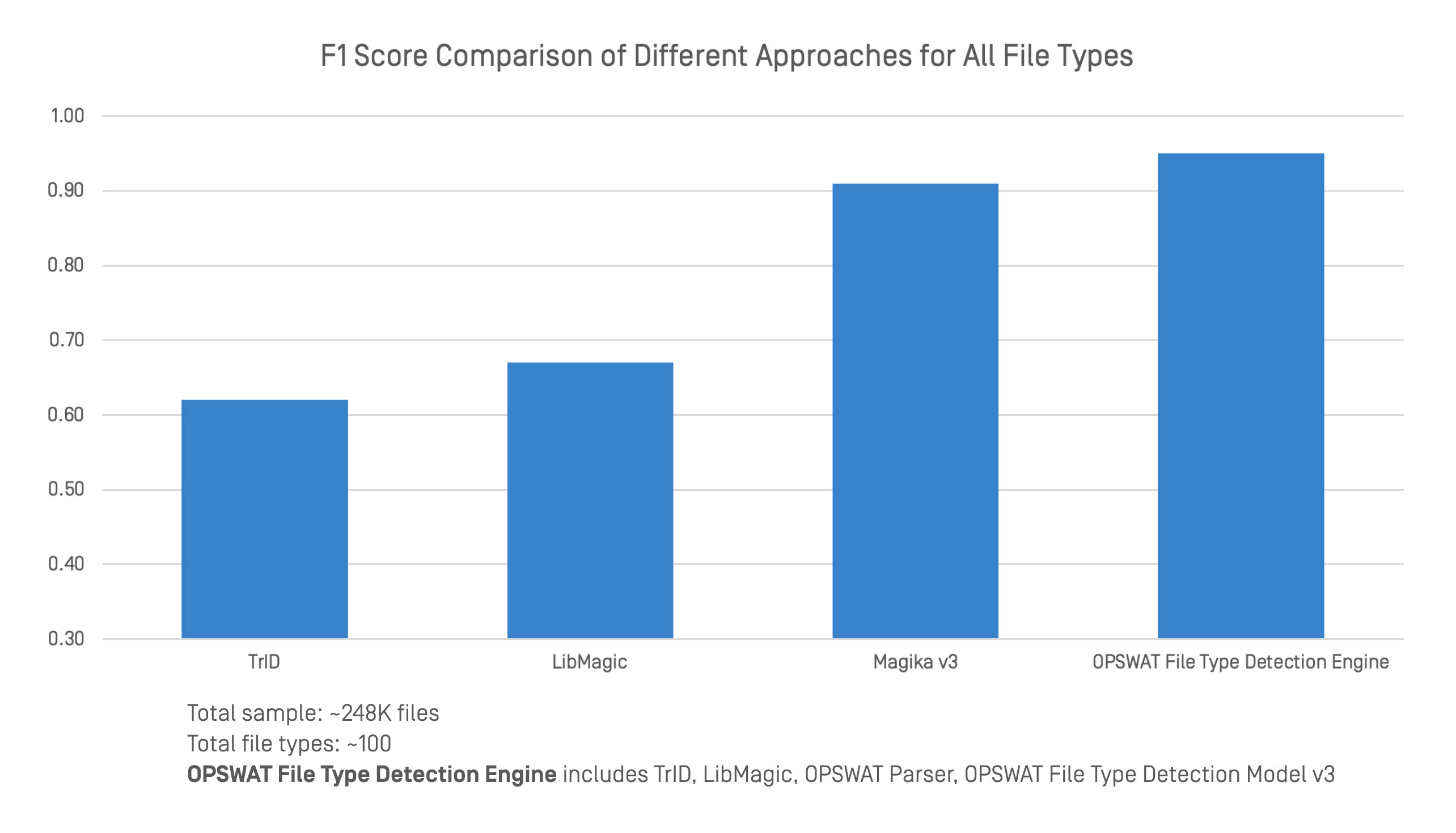
Các OPSWAT Công cụ phát hiện loại tệp tích hợp nhiều kỹ thuật, bao gồm TrID, LibMagic và OPSWAT Các công nghệ riêng của 'như trình phân tích cú pháp nâng cao và Mô hình Phát hiện Loại Tệp v3. Phương pháp kết hợp này mang lại khả năng phân loại mạnh mẽ và đáng tin cậy hơn trên cả định dạng có cấu trúc và không có cấu trúc.
Trong thử nghiệm benchmark, công cụ này đạt được độ chính xác tổng thể cao hơn bất kỳ công cụ nào riêng lẻ. Mặc dù TrID, LibMagic và Magika v3 hoạt động tốt ở một số khía cạnh nhất định, độ chính xác của chúng giảm khi tiêu đề tệp bị thiếu hoặc nội dung không rõ ràng. Bằng cách kết hợp phát hiện truyền thống với phân tích nội dung chuyên sâu, OPSWAT duy trì hiệu suất nhất quán ngay cả khi cấu trúc yếu hoặc cố tình gây hiểu lầm.
Tệp văn bản và tập lệnh
Các định dạng văn bản và tập lệnh thường liên quan đến các mối đe dọa qua tệp và chuyển động ngang. Chúng tôi đã tiến hành một thử nghiệm tập trung trên 169.000 tệp ở các định dạng như .sh, .py, .ps1, và .conf.
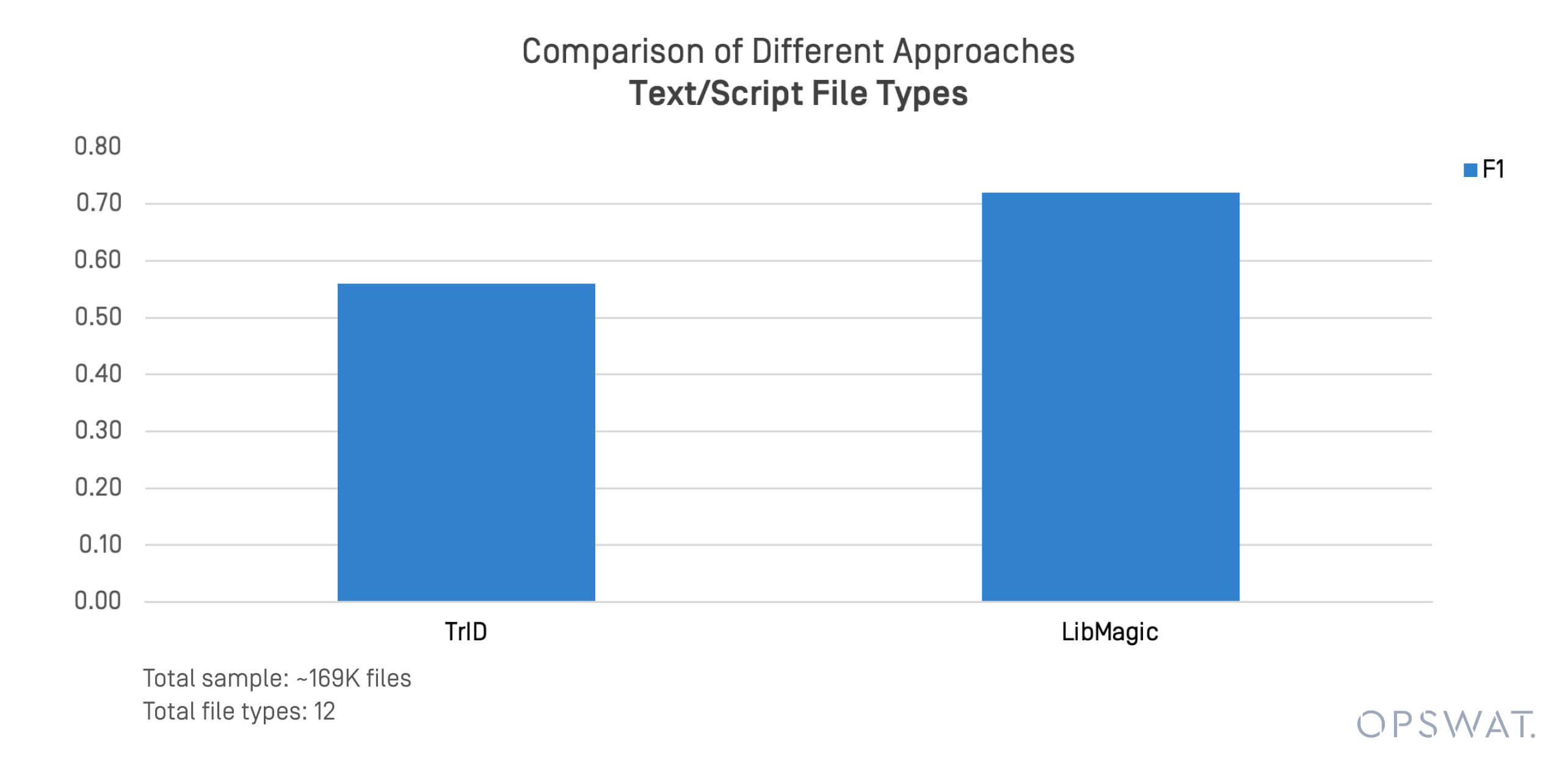
TrID và LibMagic cho thấy những hạn chế trong việc phát hiện các tệp phi cấu trúc này. Hiệu suất của chúng giảm nhanh chóng khi nội dung tệp lệch khỏi các mẫu byte dự kiến.
Mô hình phát hiện loại tệp v3 vs Magika v3
Chúng tôi đã đánh giá OPSWAT Mô hình phát hiện loại tệp v3 so với Magika v3, trình phân loại AI nguồn mở của Google, trên 30 loại tệp văn bản và tập lệnh bằng cách sử dụng cùng một tập dữ liệu 500.000 tệp.
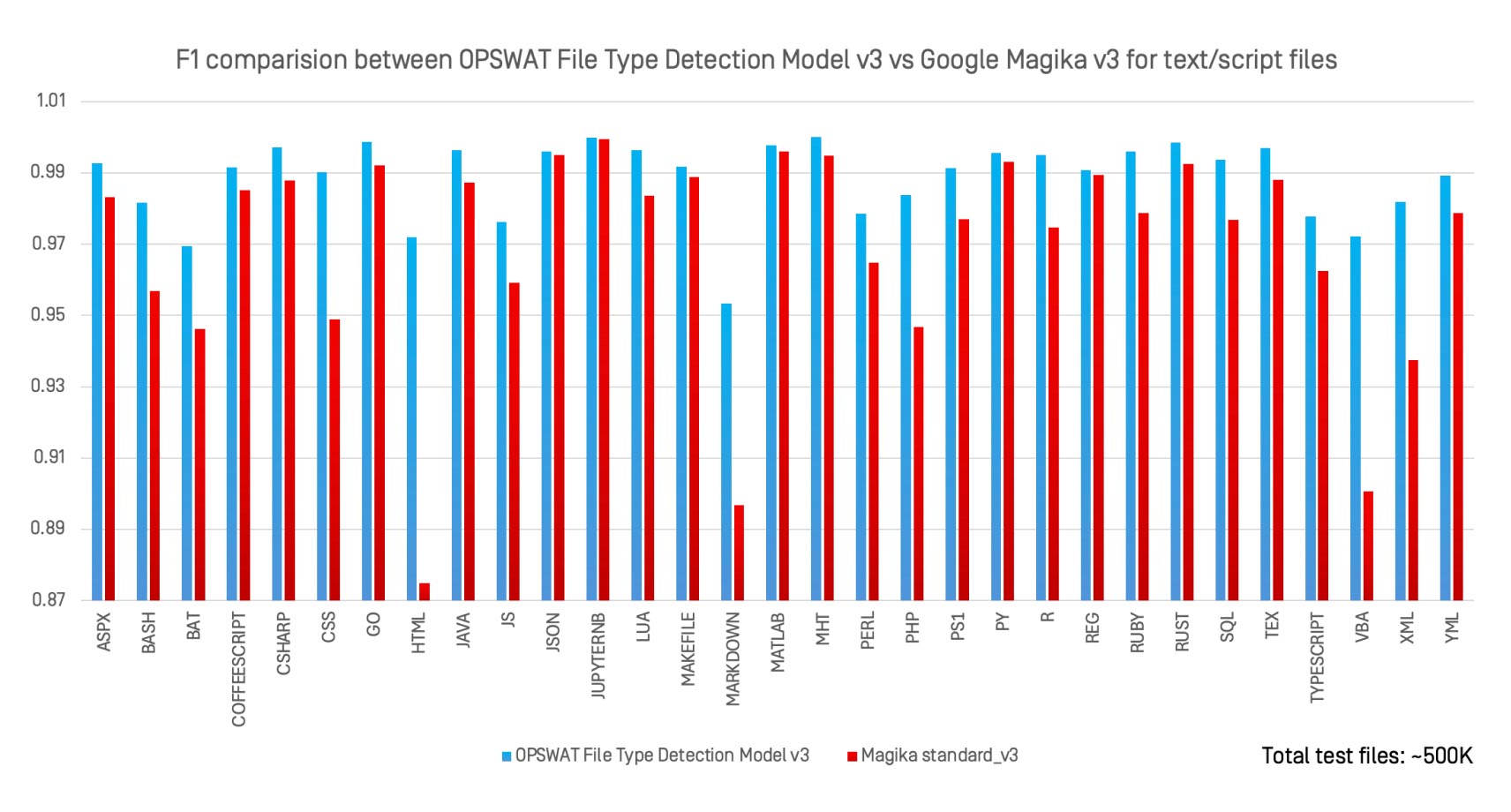
Những quan sát chính:
- Mô hình phát hiện loại tệp v3 có hiệu suất ngang bằng hoặc vượt trội hơn Magika ở hầu hết mọi định dạng.
- Những lợi ích mạnh nhất được thấy ở các định dạng được xác định một cách lỏng lẻo như
.bat, .perl, .html,Và .xml. - Không giống như Magika, được thiết kế để nhận dạng mục đích chung, File Type Detection Model v3 được tối ưu hóa cho các định dạng có rủi ro cao, trong đó việc phân loại sai có thể gây ra hậu quả nghiêm trọng về bảo mật.
Các trường hợp sử dụng hàng đầu
Secure Tải lên, Tải xuống và Chuyển tệp
Ngăn chặn các tệp tin ngụy trang hoặc độc hại xâm nhập vào môi trường của bạn thông qua cổng thông tin web, tệp đính kèm email hoặc hệ thống truyền tệp. Tính năng phát hiện được tăng cường bằng AI vượt xa các tiện ích mở rộng và tiêu đề MIME để xác định các tập lệnh, macro hoặc tệp thực thi nhúng bên trong các tệp đã đổi tên.
Đường ống DevSecOps
Ngăn chặn các hiện vật không an toàn trước khi chúng làm ô nhiễm môi trường xây dựng hoặc triển khai phần mềm của bạn. Bằng cách xác thực loại tệp thực sự dựa trên nội dung thực tế, MetaDefender Core đảm bảo rằng chỉ những định dạng được chấp thuận mới được di chuyển qua đường ống CI/CD, giảm thiểu nguy cơ tấn công chuỗi cung ứng và duy trì sự tuân thủ các biện pháp phát triển an toàn.
Thực thi tuân thủ
Việc phát hiện chính xác loại tệp là điều cần thiết để đáp ứng các yêu cầu quy định như HIPAA, PCI DSS, GDPR và NIST 800-53, vốn yêu cầu kiểm soát chặt chẽ tính toàn vẹn dữ liệu và bảo mật hệ thống. Việc phát hiện và chặn các loại tệp giả mạo hoặc trái phép giúp thực thi các chính sách ngăn chặn việc lộ dữ liệu nhạy cảm, duy trì khả năng sẵn sàng kiểm tra và tránh các hình phạt tốn kém.
Kết luận:
Các trình phân loại tệp đa năng như Magika rất hữu ích cho việc phân loại nội dung rộng. Tuy nhiên, trong an ninh mạng, độ chính xác trọng yếu hơn phạm vi bảo vệ. Chỉ cần một tập lệnh phân loại sai hoặc một macro gắn nhãn sai cũng có thể tạo nên sự khác biệt giữa ngăn chặn và xâm phạm.
Các OPSWAT Công cụ Phát hiện Loại Tệp mang lại độ chính xác đó. Bằng cách kết hợp phân tích loại tệp được tăng cường bằng AI với các phương pháp phát hiện đã được chứng minh, công cụ này cung cấp một lớp phân loại đáng tin cậy mà các công cụ truyền thống không thể làm được, đặc biệt là ở các định dạng mơ hồ hoặc không có cấu trúc. Mục tiêu không phải là thay thế mọi thứ; mà là củng cố các điểm yếu trọng yếu trong ngăn xếp bảo mật của bạn bằng khả năng phát hiện theo ngữ cảnh, theo thời gian thực.

